Marquez: An Open Source Metadata Management Tool
Marquez is an open source metadata service for the collection, aggregation, and visualization of data ecosystem metadata. It maintains dataset consumption and production, provides global visibility into job runtime and dataset access frequency, provides centralized dataset lifecycle management, and more. WeWork released and open-sourced Marquez.
Open Source Metadata Management Tool
Features of Marquez:
1. Centralized metadata management supports:
- Data lineage
- Data governance
- Data health
- Data discovery and exploration
2. Accurate high-dimensional data model:
- Jobs
- Datasets
3. Easily collect metadata via specified metadata APIs:
- Pay attention to dataset data
- Reinforce job and dataset ownership
- Simple operation and design with minimal dependencies
4. The RESTful API supports complex integration with other systems:
- Airflow
- Amundsen
- Dagster
- Designed to promote a healthy data ecosystem where team members in an organization can seamlessly share and securely rely on each other’s datasets with confidence.
Why Choose Marquez?
Marquez supports highly flexible data lineage queries across full datasets, while reliably and efficiently correlating jobs and their (upstream and downstream) dependencies between generating and consuming datasets.
The Design of Marquez
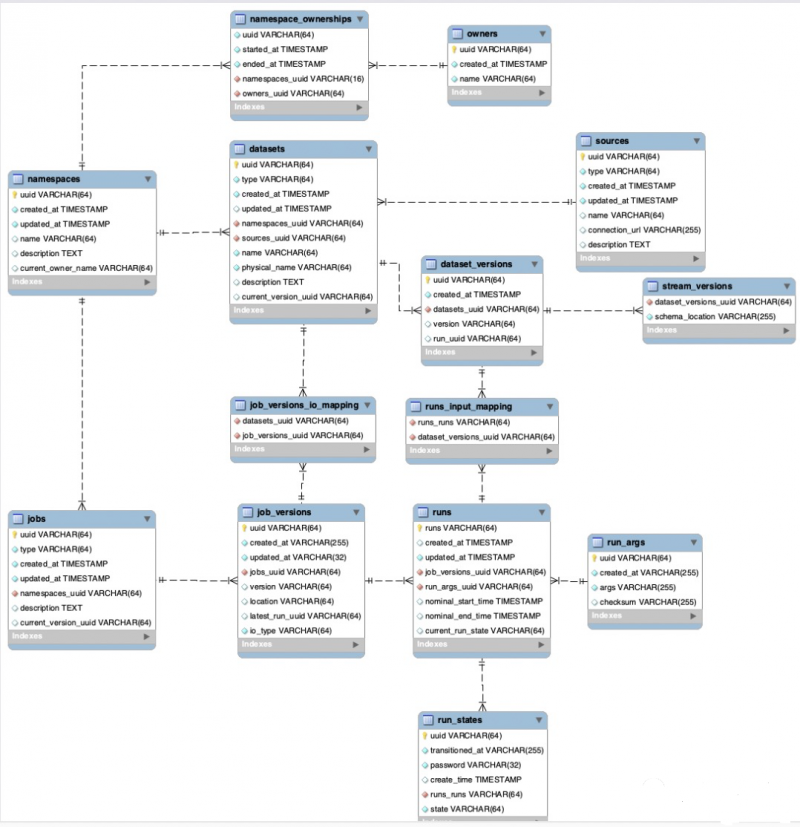
Marquez is a modular system that enables metadata management as a highly scalable and extensible de-platformed solution. It consists of the following systems:
- Metadata Repository: Stores all job and dataset metadata, including full history of job runs and job-level statistics (eg: total run time, average run time, success/failure, etc.).
- Metadata API: A RESTful API enables a diverse set of clients to collect metadata around the production and consumption of datasets.
- Metadata UI: for dataset discovery, connecting multiple datasets and exploring their dependency graph.
Open Source Metadata Management Tool
To facilitate adoption and enable different data processing applications to have metadata collection as a core requirement of their design, Marquez provides language-specific clients that implement the metadata API. As part of the initial release, it supports Java and Python.
The metadata API is an abstraction for recording information about the production and use of datasets. It is a low-latency, high-availability stateless layer responsible for encapsulating persistent metadata and collection lineage information. The API allows clients to collect and/or obtain dataset information from a metadata repository.
Metadata needs to be collected, organized, and stored for rich exploratory queries through the metadata UI. The metadata repository is an abstract catalog of dataset information compressed and cleaned by the metadata API.
The Data Model of Marquez
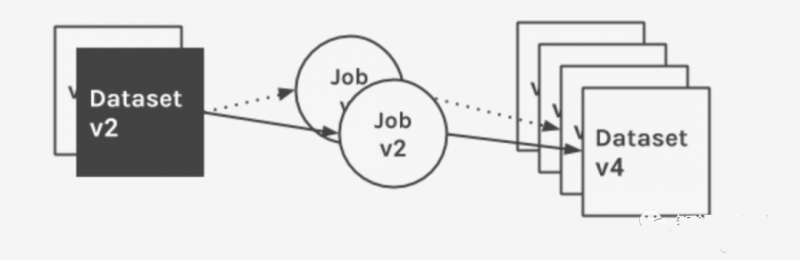
Marquez’s data model emphasizes the immutability and just-in-time processing of datasets. Datasets are generated by job runs, and the value matters. Job runs are linked with version codes and produce one or more immutable version outputs. Changes to the dataset are recorded at various points in the job execution, including the success or failure of the run itself, through calls to the lightweight API.
The figure below shows the metadata collected and cataloged for a given job over multiple runs, and the time-series changes applied to its input dataset.
Open Source Metadata Management Tool
- Job: The job contains an owner, unique name, version, and an optional description. A job defines one or more version inputs as dependencies and one or more version outputs as artifacts. Note that a job may define only input datasets or only output datasets.
- Job Version: A read-only immutable version of the job, with a uniquely referenced link, encoded in storage to ensure source code reproduction. A job version associates one or more input and output datasets to a job definition (the flow of data through various jobs is important for documenting lineage information). These associations categorize source links and provide a powerful visual flow of data.
- Dataset: A dataset has an owner, unique name, schema, version, and an optional description. The dataset is contained in the data source. Data sources can group physical datasets into their physical sources. Each dataset has a version pointer to the historical changeset, maintained by Marquez. When dataset changes are committed back to Marquez, a unique version ID is generated, stored, then set to the current version, and the pointer is updated internally.
- Dataset Version: The read-only immutable version of the dataset. Each version can be read independently, has a unique ID, and maps to changes to the dataset to preserve its state at a specific point in time. The latest version ID is only updated when changes to the dataset are logged. To compute distinct version IDs, Marquez applies versioning capabilities to a set of properties corresponding to the underlying data source’s dataset.
Conclusion
Thank you for reading our article and we hope it can help you to have a better understanding of Marquez: an open source metadata management tool. If you want to learn more about metadata management, we would like to advise you to visit Gudu SQLFlow for more information.
As one of the best data lineage tools available on the market today, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display. (Published by Ryan on Jun 28, 2022)
Try Gudu SQLFlow Live

If you enjoy reading this, then, please explore our other articles below:


