Marquez: オープンソースのメタデータ管理ツール
Marquez は、データ エコシステム メタデータの収集、集約、および視覚化のためのオープン ソース メタデータ サービスです。データセットの消費と生産を維持し、ジョブの実行時間とデータセットへのアクセス頻度をグローバルに可視化し、一元化されたデータセットのライフサイクル管理などを提供します。 WeWork は Marquez をリリースし、オープンソース化しました。
オープンソースのメタデータ管理ツール
マルケスの特徴:
1. 一元化されたメタデータ管理により、以下がサポートされます。
- データ系統
- データガバナンス
- データの健全性
- データの発見と探索
2. 正確な高次元データ モデル:
- ジョブ
- データセット
3. 指定されたメタデータ API を介してメタデータを簡単に収集します。
- データセットのデータに注意する
- ジョブとデータセットの所有権を強化する
- 依存関係を最小限に抑えたシンプルな操作と設計
4. RESTful API は、他のシステムとの複雑な統合をサポートします。
- 気流
- アムンセン
- ダグスター
- 組織内のチーム メンバーがシームレスに共有し、自信を持って互いのデータセットを安全に信頼できる、健全なデータ エコシステムを促進するように設計されています。
マルケスを選ぶ理由
Marquez は、データセットの生成と使用の間でジョブとその (上流と下流の) 依存関係を確実かつ効率的に関連付けながら、完全なデータセット全体で非常に柔軟なデータ系列クエリをサポートします。
マルケスのデザイン
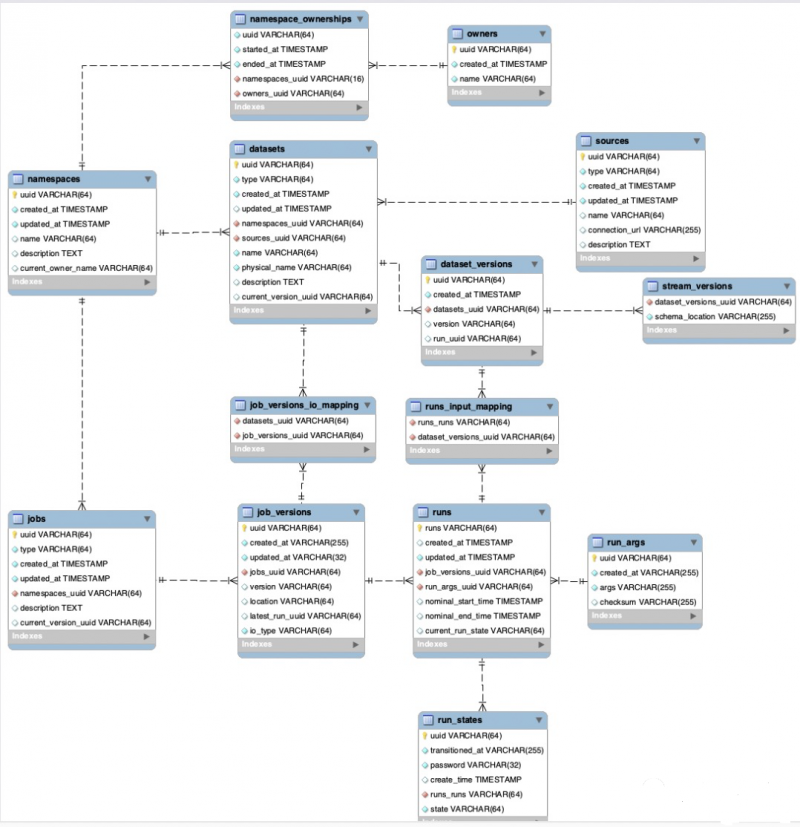
Marquez はモジュラー システムであり、 メタデータ管理 スケーラビリティと拡張性に優れたデプラットフォーム ソリューションとして。以下のシステムで構成されています。
- メタデータ リポジトリ: ジョブ実行の完全な履歴とジョブ レベルの統計 (例: 合計実行時間、平均実行時間、成功/失敗など) を含む、すべてのジョブとデータセットのメタデータを格納します。
- メタデータ API: RESTful API を使用すると、さまざまなクライアント セットがデータセットの生成と消費に関するメタデータを収集できます。
- メタデータ UI: データセットの検出、複数のデータセットの接続、およびそれらの依存関係グラフの探索用。
オープンソースのメタデータ管理ツール
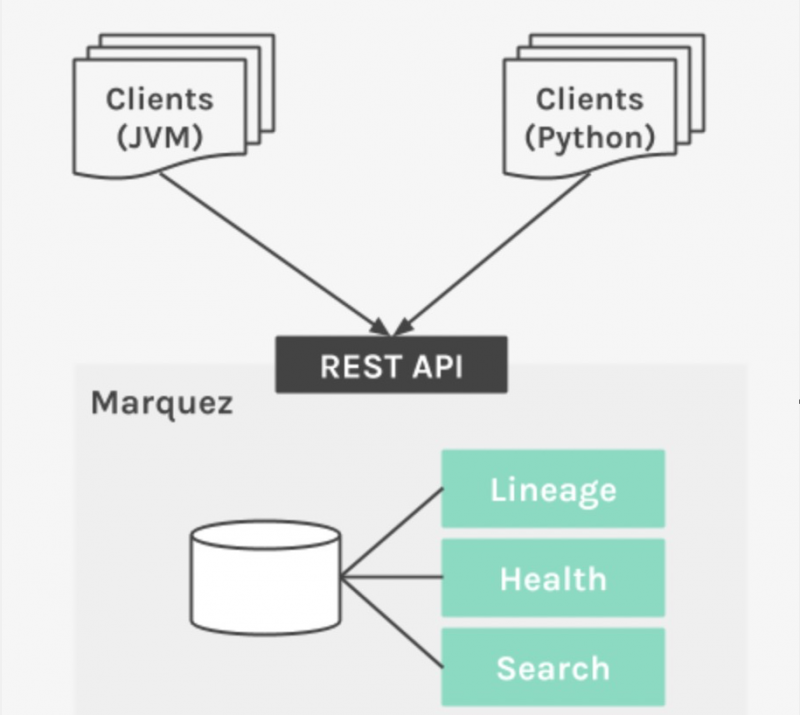
採用を促進し、さまざまなデータ処理アプリケーションがメタデータ コレクションを設計のコア要件として持つことができるようにするために、Marquez はメタデータ API を実装する言語固有のクライアントを提供します。初期リリースの一部として、Java と Python をサポートしています。
メタデータ API は、データセットの作成と使用に関する情報を記録するための抽象化です。これは、永続的なメタデータとコレクション系統情報をカプセル化する役割を担う、低レイテンシで高可用性のステートレス レイヤーです。 API を使用すると、クライアントはメタデータ リポジトリからデータセット情報を収集および/または取得できます。
メタデータは、メタデータ UI を介して豊富な探索的クエリのために収集、整理、保存する必要があります。メタデータ リポジトリは、メタデータ API によって圧縮および消去されたデータセット情報の抽象的なカタログです。
マルケスのデータモデル
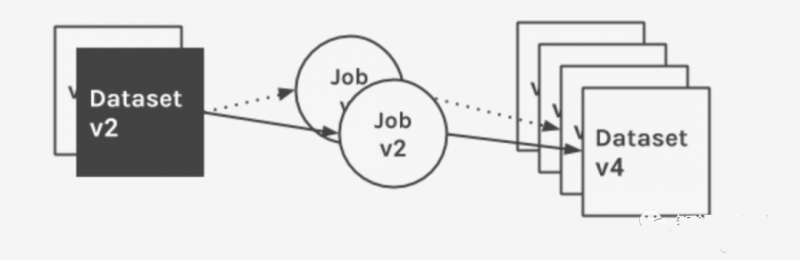
Marquez のデータ モデルは、データセットの不変性とジャストインタイム処理を強調しています。データセットはジョブの実行によって生成され、値が重要です。ジョブの実行はバージョン コードにリンクされており、1 つ以上の不変のバージョン出力が生成されます。データセットへの変更は、軽量 API の呼び出しを通じて、実行自体の成功または失敗を含む、ジョブ実行のさまざまな時点で記録されます。
次の図は、複数回の実行で特定のジョブに対して収集およびカタログ化されたメタデータと、その入力データセットに適用された時系列の変更を示しています。
オープンソースのメタデータ管理ツール
- ジョブ: ジョブには、所有者、一意の名前、バージョン、およびオプションの説明が含まれます。ジョブは、1 つ以上のバージョン入力を依存関係として定義し、1 つ以上のバージョン出力をアーティファクトとして定義します。ジョブは、入力データセットのみ、または出力データセットのみを定義できることに注意してください。
- ジョブ バージョン: ソース コードの再現を保証するためにストレージにエンコードされた、一意に参照されるリンクを含む、ジョブの読み取り専用の不変バージョン。ジョブ バージョンは、1 つ以上の入力および出力データセットをジョブ定義に関連付けます (さまざまなジョブを介したデータの流れは、系列情報を文書化するために重要です)。これらの関連付けは、ソース リンクを分類し、強力なビジュアル フローのデータを提供します。
- データセット: データセットには、所有者、一意の名前、スキーマ、バージョン、およびオプションの説明があります。データセットはデータ ソースに含まれています。データ ソースは、物理データセットを物理ソースにグループ化できます。各データセットには、Marquez によって管理されている過去の変更セットへのバージョン ポインターがあります。データセットの変更が Marquez にコミットされると、一意のバージョン ID が生成されて保存され、現在のバージョンに設定され、ポインタが内部的に更新されます。
- データセット バージョン: データセットの読み取り専用の不変バージョン。各バージョンは個別に読み取ることができ、一意の ID を持ち、特定の時点での状態を保持するためにデータセットへの変更にマップされます。最新バージョン ID は、データセットへの変更がログに記録されたときにのみ更新されます。個別のバージョン ID を計算するために、Marquez は、基になるデータ ソースのデータセットに対応する一連のプロパティにバージョン管理機能を適用します。
結論
この記事をお読みいただきありがとうございます。この記事が、オープン ソースのメタデータ管理ツールである Marquez についての理解を深めるのに役立つことを願っています。メタデータ管理について詳しく知りたい場合は、次のサイトにアクセスすることをお勧めします。 Gudu SQLFlow 詳細については。
その一つとして 最高のデータ系統ツール 現在市場に出回っている Gudu SQLFlow は、SQL スクリプト ファイルを分析し、データ系統を取得して視覚的に表示できるだけでなく、ユーザーがデータ系統を CSV 形式で提供し、視覚的に表示することもできます。 (2022 年 6 月 28 日に Ryan により公開)

これを読んで楽しんでいる場合は、以下の他の記事をご覧ください。


