Metadata Architecture Evolution
Metadata management is the foundation and source of the data governance system. At different stages of technological development, its status and role in enterprise data governance are very different. Today, data has the characteristics of multi-source, heterogeneity, and value difference, and these characteristics are accelerated and amplified in the process of crazy data growth. In addition, after the computing power of enterprises has generally increased significantly, there is a strong expectation that data should be mined in a deeper way to exert greater value.
As the support team of enterprise data, the question we hear the most in daily life is “how to obtain the correct data set”. We’ve come to realize that while we’ve built highly scalable data storage, real-time computing, and more, our teams are still wasting time finding the right datasets to develop and analyze. That is, we still lack the management of data assets. In fact, there are many companies that offer open source solutions to the above problems, namely data discovery and metadata management tools.
However, because it is limited by the business and technology development needs of various enterprises at various stages, the selection of functions, applications and focus directions for the construction of relevant management platforms by enterprises often varies widely. This article aims to introduce the architectural evolution of metadata management tools.
Simply put, metadata management is the efficient organization and management of data assets using metadata. It can also help data professionals collect, organize, access and enrich metadata, and support upper-layer applications such as data maps, data specification, cost control, quality inspection, and security auditing.
Thirty years ago, a data asset might have been just a table in an Oracle database. However, in the modern enterprise, we have a bewildering array of different types of data assets. It may be a relational database table, an object in a non-relational database, a piece of real-time streaming data, an indicator, a portrait, or a dial or a panel in a BI tool.
A modern metadata management system should cover all types of data assets and be able to help data workers make better use of related data assets. Therefore, the core functions of the metadata management system applicable to today are as follows:
- Search and discovery: data tables, fields, tags, usage information;
- Access control: access control groups, users, policies;
- Data lineage: pipeline execution, query;
- Compliance: classification of data privacy/compliance annotation types;
- Data management: data source configuration, ingest configuration, retention configuration, data purge policy;
- AI interpretability, reproducibility: feature definition, model definition, training run execution, problem statement;
- Data manipulation: pipeline execution, processed data partition, data statistics;
- Data quality: data quality rule definition, rule execution result, data statistics.
Metadata Architecture Evolution:
The first-generation metadata architecture is generally based on extraction. Metadata is obtained by connecting and querying data sources (Hive, Kafka, etc.), and only external storage and query services are required. It is usually a classic monolithic front end that connects to the primary storage for queries (usually MySQL/Postgres), a search index (usually Elasticsearch) that serves search queries when the query reaches the “recursive query” limit of a relational database , may be upgraded to use a graph database (usually Neo4j) as the query index.
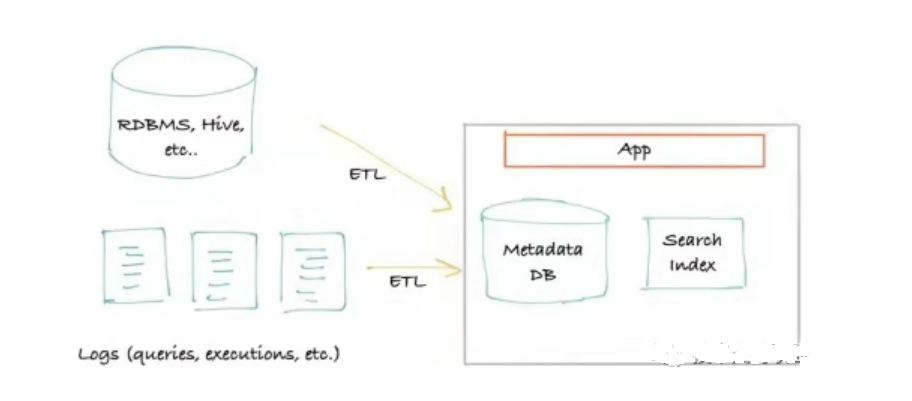
Metadata Architecture
The advantages of this metadata architecture are obvious: the architecture is simple, and it can be quickly constructed with only storage and a search engine, with high efficiency and low cost. But the shortcomings are also obvious: it has a considerable impact on the performance of the data source, and there are many requirements for the extraction time, frequency, and load. In addition, as the real-time requirements are getting higher and higher, this metadata architecture is becoming more and more inapplicable.
The open source product Amundsen has a first-generation architecture, but it focuses on the function of achieving search ranking, which is very powerful.
The second-generation metadata architecture is a three-tier application architecture based on service splitting. This architecture splits the monolithic application out of metadata services. The service provides an API that allows metadata to be written to the system using a push mechanism, and a metadata read API for programs that need to read metadata programmatically.
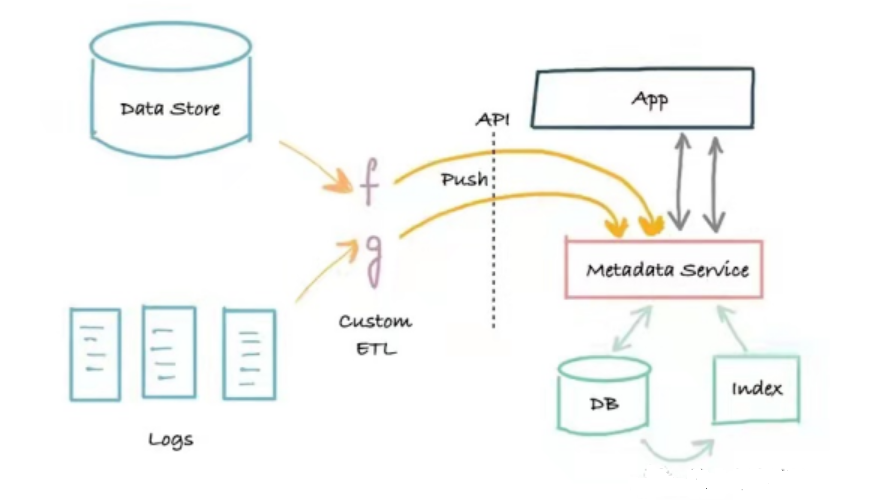
Metadata Architecture
The advantage of this architecture is that it is implemented based on the push method, which builds a bridge between the metadata producer and the metadata service, and solves the real-time problem. The downside is that there are no logs. When something goes wrong, it can be difficult to reliably bootstrap (recreate) or fix search and graph indexes. Second-generation metadata systems can often be a reliable search and discovery portal for a company’s data assets, addressing the core needs of data workers, and Marquez has a second-generation metadata architecture.
The third-generation metadata architecture is an event-based metadata management architecture, which is based on log push + model decoupling. Users can interact with the metadata database in different ways according to their needs and can define extended metadata models.
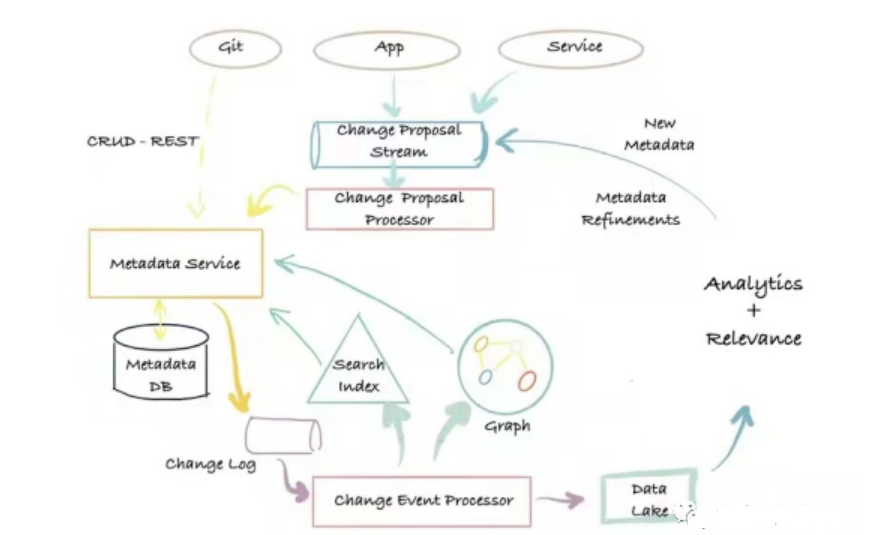
Metadata Architecture
Its main advantages are: flexibility, high scalability, low-latency search, the ability to perform full-text and ranking searches on metadata attributes, graph queries that support metadata relationships, and full scan and analysis capabilities. The disadvantage is: there are many dependent components, and the operation and maintenance cost is high. The representative systems of the third-generation metadata architecture are Altas and DataHub.
A simple visual representation of today’s metadata management platform landscape (including non-open source):
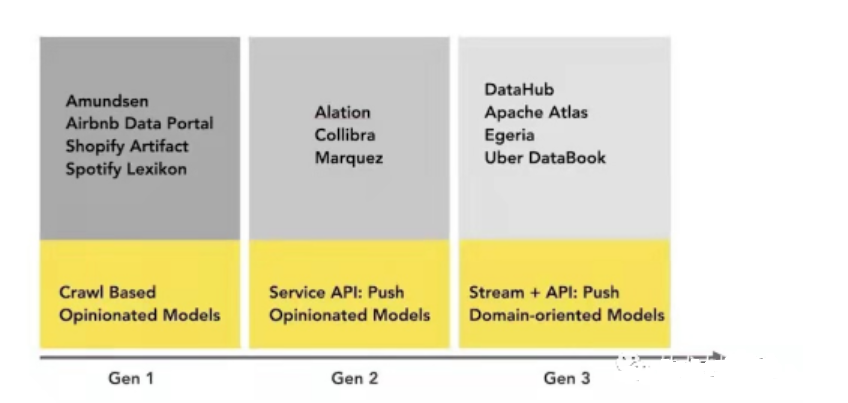
Conclusion
Thank you for reading our article and we hope it can help you to have a better understanding of the metadata architecture evolution. If you want to learn more about metadata, we would like to advise you to visit Gudu SQLFlow for more information.
As one of the best data lineage tools available on the market today, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display. (Published by Ryan on Jun 29, 2022)
Try Gudu SQLFlow Live

If you enjoy reading this, then, please explore our other articles below:


