Data Lineage Create External Table | Gudu SQLFlow
In the data warehouse, the original data is always from the mass storage such as Amazon S3, Google Cloud Storage, and Microsoft Azure, and those data will be loaded into the system such as BigQuery, Snowflake, Redshift, and Microsoft Azure. One of the methods used to load or use those data is using the create external table SQL statement. The data lineage from the external file to the external table can be captured easily by the Gudu SQLFlow by parsing the create external table SQL query. With this data on hand, Gudu SQLFlow greatly simplifies the ability to trace errors back to the root cause in a data analytics process.
Data Lineage Create External Table
In the article, we will introduce the create external table SQL statement used in BigQuery, Snowflake, Redshift, and Microsoft Azure, and see the data lineage generated by the Gudu SQLFlow after analyzing the SQL script.
BigQuery create external table
External tables let BigQuery query data that is stored outside of BigQuery storage. For more information about external tables, see introduction to external data sources.
Gudu SQLFlow can analyze BigQuery create external table statement and create the data lineage after analyzing this SQL statement.
Here is a BigQuery create external table SQL query:
CREATE OR REPLACE EXTERNAL TABLE dataset.CsvTable
(
x INT64,
y STRING
)
OPTIONS (
format = 'CSV',
uris = ['gs://bucket/path1.csv'],
field_delimiter = '|',
max_bad_records = 5
);The data lineage generated for the above SQL here, as you can see the gs://bucket/path1.csv file stored at Google Storage is treated as the source of the dataset.CsvTable external table.

Snowflake create external table
Snowflake creates an external table to reads data from a set of one or more files in a specified external stage and outputs the data in a single VARIANT column. Create external table statement creates a new external table in the current/specified schema or replaces an existing external table.
Before creating an external table, we need to create an external stage for the storage location where the data files are stored.
create stage s1
url='s3://mybucket/files/logs/'
...
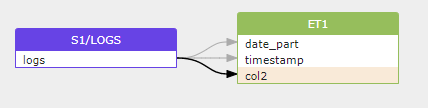
;Create the partitioned external table:
create external table et1(
date_part date as to_date(split_part(metadata$filename, '/', 3)
|| '/' || split_part(metadata$filename, '/', 4)
|| '/' || split_part(metadata$filename, '/', 5), 'YYYY/MM/DD'),
timestamp bigint as (value:timestamp::bigint),
col2 varchar as (value:col2::varchar))
partition by (date_part)
location=@s1/logs/
auto_refresh = true
file_format = (type = parquet)
aws_sns_topic = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket';Gudu SQLFlow can process Snowflake create external table query statement and build a data lineage between the files in the external stage and the external table like this:
In Snowflake, data from external files can also be moved to the table using copy into SQL statement and Gudu SQLFlow can also detect the data lineage in the copy into SQL query statement.
SQL Server and Azure Synapse Analytics
Create external table command creates an external table for PolyBase to access data stored in a Hadoop cluster or Azure blob storage PolyBase external table that references data stored in a Hadoop cluster or Azure blob storage.
In Azure Synapse Analytics, the created external table:
- Query Hadoop or Azure blob storage data with Transact-SQL statements.
- Import and store data from Hadoop or Azure blob storage.
- Import and store data from Azure Data Lake Store.
In order to create an external table, an external data source must be created at first:
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
)Then, create an external table using this SQL query:
CREATE EXTERNAL TABLE [dbo].[DimProductexternal]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
) ;The data lineage generated by Gudu SQLFlow after parsing the create external table statement is:

AWS Redshift create external table
You can create an external table in Amazon Redshift, AWS Glue, Amazon Athena, or an Apache Hive metastore. If your external table is defined in AWS Glue, Athena, or a Hive metastore, you first create an external schema that references the external database. Then you can reference the external table in your SELECT statement by prefixing the table name with the schema name, without needing to create the table in Amazon Redshift.
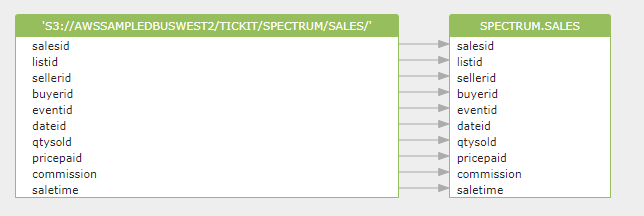
The following example creates a table named SALES in the Amazon Redshift external schema named spectrum. The data is in tab-delimited text files.
create external table spectrum.sales(
salesid integer,
listid integer,
sellerid integer,
buyerid integer,
eventid integer,
dateid smallint,
qtysold smallint,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp)
row format delimited
fields terminated by 't'
stored as textfile
location 's3://awssampledbuswest2/tickit/spectrum/sales/'
table properties ('numRows'='172000');The data lineage generated by Gudu SQLFlow after parsing the above SQL is:
Conclusion
Thank you for reading our article and if it can help you to have a better understanding of how does data lineage create external table, we would be very happy. If you want to find more about data lineage create external table, we would like to advise you to visit our website Gudu SQLFlow for more information. (Edited by Ryan on Apr 25, 2022)
Try Gudu SQLFlow Live

If you enjoy reading this, then, please explore our other articles below:


