データ リネージ 外部テーブルの作成 | Gudu SQLFlow
データ ウェアハウスでは、元のデータは常に Amazon S3、Google Cloud Storage、Microsoft Azure などの大容量ストレージから取得され、それらのデータは BigQuery、Snowflake、Redshift、Microsoft Azure などのシステムに読み込まれます。これらのデータをロードまたは使用するために使用される方法の 1 つは、create external table SQL ステートメントを使用することです。外部ファイルから外部テーブルへのデータ系統は、 Gudu SQLFlow create external table SQL クエリを解析します。このデータを手元に置いて、 Gudu SQLFlow データ分析プロセスでエラーを根本原因まで追跡する機能が大幅に簡素化されます。
データ リネージュ 外部テーブルの作成
この記事では、BigQuery、Snowflake、Redshift、Microsoft Azure で使用される create external table SQL ステートメントを紹介し、 Gudu SQLFlow SQLスクリプトを分析した後。
BigQuery が外部テーブルを作成
外部テーブルを使用すると、BigQuery は BigQuery ストレージの外部に保存されているデータをクエリできます。外部テーブルの詳細については、を参照してください。 外部データ ソースの紹介.
Gudu SQLFlow BigQuery create external table ステートメントを分析し、 データ系統 このSQL文を分析した後。
BigQuery create external table SQL クエリを次に示します。
CREATE OR REPLACE EXTERNAL TABLE dataset.CsvTable ( x INT64, y STRING ) OPTIONS ( format = 'CSV', uris = ['gs://bucket/path1.csv'], field_delimiter = '|', max_bad_records = 5 );ここで上記の SQL に対して生成されたデータ系統は、Google ストレージに保存されている gs://bucket/path1.csv ファイルが dataset.CsvTable 外部テーブルのソースとして扱われることがわかります。

Snowflakeは外部テーブルを作成します
Snowflake は、指定された外部ステージの 1 つ以上のファイルのセットからデータを読み取り、単一の VARIANT 列にデータを出力する外部テーブルを作成します。 外部表ステートメントの作成 現在の/指定されたスキーマに新しい外部テーブルを作成するか、既存の外部テーブルを置き換えます。
外部テーブルを作成する前に、次のことを行う必要があります 外部ステージを作成する データファイルが保存されているストレージの場所。
ステージ s1 の作成 url='s3://mybucket/files/logs/' ... ;パーティション化された外部テーブルを作成します。
create external table et1( date_part date as to_date(split_part(metadata$filename, '/', 3) || '/' || split_part(metadata$filename, '/', 4) || '/' || split_part(metadata$filename, '/) ', 5), 'YYYY/MM/DD'), タイムスタンプ bigint as (value:timestamp::bigint), col2 varchar as (value:col2::varchar)) partition by (date_part) location=@s1/logs/ auto_refresh = true file_format = (type = parquet) aws_sns_topic = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket';Gudu SQLFlow は Snowflake の create external table クエリ ステートメントを処理し、次のように外部ステージのファイルと外部テーブルの間にデータ系統を構築できます。
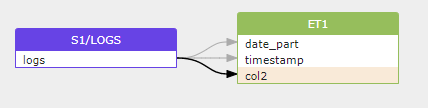
Snowflakeでは、外部ファイルからのデータも、次を使用してテーブルに移動できます。 にコピー SQL ステートメントと Gudu SQLFlow は、SQL クエリ ステートメントへのコピーでデータ系統を検出することもできます。
SQL Server と Azure Synapse Analytics
Create external table コマンドは、PolyBase が Hadoop クラスターに格納されているデータにアクセスするための外部テーブル、または Hadoop クラスターまたは Azure Blob Storage に格納されているデータを参照する Azure Blob Storage PolyBase 外部テーブルを作成します。
Azure Synapse Analytics では、作成された外部テーブル:
- Transact-SQL ステートメントを使用して、Hadoop または Azure BLOB ストレージ データのクエリを実行します。
- Hadoop または Azure BLOB ストレージからデータをインポートして保存します。
- Azure Data Lake Store からデータをインポートして保存します。
外部テーブルを作成するには、最初に外部データ ソースを作成する必要があります。
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore WITH (TYPE = HADOOP, LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net' )次に、次の SQL クエリを使用して外部テーブルを作成します。
CREATE EXTERNAL TABLE [dbo].[DimProductexternal] ( [ProductKey] [int] NOT NULL, [ProductLabel] nvarchar NULL, [ProductName] nvarchar NULL ) WITH ( LOCATION='/DimProduct/' , DATA_SOURCE = AzureDataLakeStore , FILE_FORMAT = TextFileFormat , REJECT_TYPE = 値、REJECT_VALUE = 0);create external table ステートメントを解析した後に Gudu SQLFlow によって生成されるデータ系統は次のとおりです。

AWS Redshift が外部テーブルを作成
Amazon Redshift、AWS Glue、Amazon Athena、または Apache Hive メタストアで外部テーブルを作成できます。外部テーブルが AWS Glue、Athena、または Hive メタストアで定義されている場合は、最初に外部データベースを参照する外部スキーマを作成します。その後、Amazon Redshift でテーブルを作成しなくても、テーブル名にスキーマ名のプレフィックスを付けることで、SELECT ステートメントで外部テーブルを参照できます。
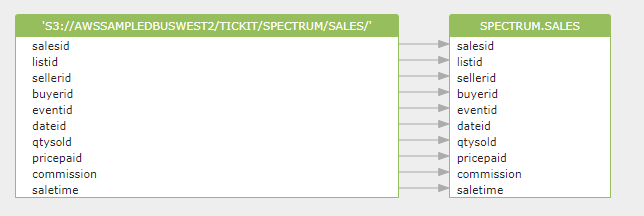
次の例では、次の名前の Amazon Redshift 外部スキーマに SALES という名前のテーブルを作成します。 スペクトラム.データはタブ区切りのテキスト ファイルです。
外部テーブルを作成します。 「t」で終了するフィールドは、テキストファイルの場所「s3://awssampledbuswest2/tickit/spectrum/sales/」として保存されます (「numRows」=「172000」)。上記の SQL を解析した後、Gudu SQLFlow によって生成されたデータ系統は次のとおりです。
結論
私たちの記事をお読みいただきありがとうございます。 データ系統はどのように外部テーブルを作成しますか、私たちはとても幸せです。詳しく知りたい方は データリネージは外部テーブルを作成します、私たちはあなたに私たちのウェブサイトを訪問することをお勧めします Gudu SQLFlow 詳細については。 (2022 年 4 月 25 日に Ryan が編集)

これを読んで楽しんでいる場合は、以下の他の記事をご覧ください。


