Marquez: Ein Open-Source-Tool zur Metadatenverwaltung
Marquez ist ein Open-Source-Metadatendienst für die Erfassung, Aggregation und Visualisierung von Metadaten aus Datenökosystemen. Er verwaltet die Nutzung und Produktion von Datensätzen, bietet globale Transparenz in Bezug auf Joblaufzeiten und Zugriffshäufigkeit, ermöglicht ein zentrales Lebenszyklusmanagement für Datensätze und vieles mehr. WeWork hat Marquez veröffentlicht und als Open Source bereitgestellt.
Open-Source-Tool zur Metadatenverwaltung
Eigenschaften von Marquez:
1. Zentralisiertes Metadatenmanagement unterstützt:
- Datenherkunft
- Datenverwaltung
- Datenintegrität
- Datenermittlung und -erkundung
2. Präzises hochdimensionales Datenmodell:
- Jobs
- Datensätze
3. Einfaches Sammeln von Metadaten über angegebene Metadaten-APIs:
- Achten Sie auf Datensatzdaten
- Stärkung des Eigentums an Jobs und Datensätzen
- Einfache Bedienung und Design mit minimalen Abhängigkeiten
4. Die RESTful API unterstützt die komplexe Integration mit anderen Systemen:
- Luftstrom
- Amundsen
- Dagster
- Entwickelt, um ein gesundes Datenökosystem zu fördern, in dem Teammitglieder in einer Organisation die Datensätze der anderen nahtlos und sicher teilen und sich darauf verlassen können.
Warum Marquez wählen?
Marquez unterstützt hochflexible Datenherkunftsabfragen über vollständige Datensätze hinweg und korreliert gleichzeitig zuverlässig und effizient Jobs und ihre (Upstream- und Downstream-)Abhängigkeiten zwischen der Generierung und Nutzung von Datensätzen.
Das Design von Marquez
Marquez ist ein modulares System, das es ermöglicht Metadatenverwaltung als hochskalierbare und erweiterbare De-Platformed-Lösung. Sie besteht aus den folgenden Systemen:
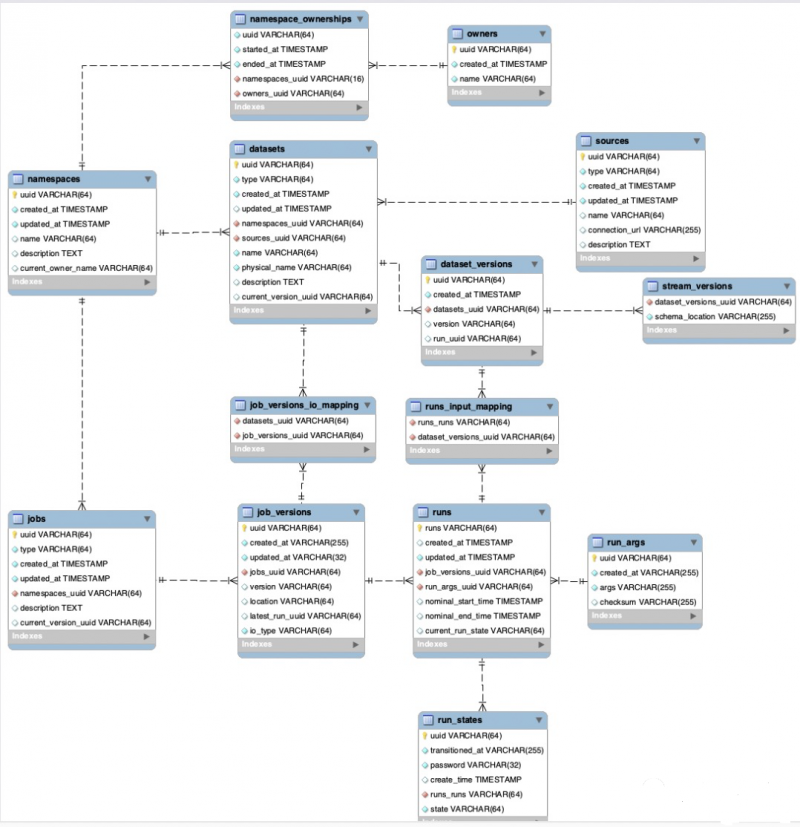
- Metadaten-Repository: Speichert alle Job- und Datensatz-Metadaten, einschließlich des vollständigen Verlaufs der Jobausführungen und Statistiken auf Jobebene (z. B. Gesamtlaufzeit, durchschnittliche Laufzeit, Erfolg/Misserfolg usw.).
- Metadaten-API: Eine RESTful-API ermöglicht einer Vielzahl von Clients, Metadaten rund um die Produktion und Nutzung von Datensätzen zu sammeln.
- Metadaten-UI: zum Erkennen von Datensätzen, zum Verbinden mehrerer Datensätze und zum Erkunden ihres Abhängigkeitsdiagramms.
Open-Source-Tool zur Metadatenverwaltung
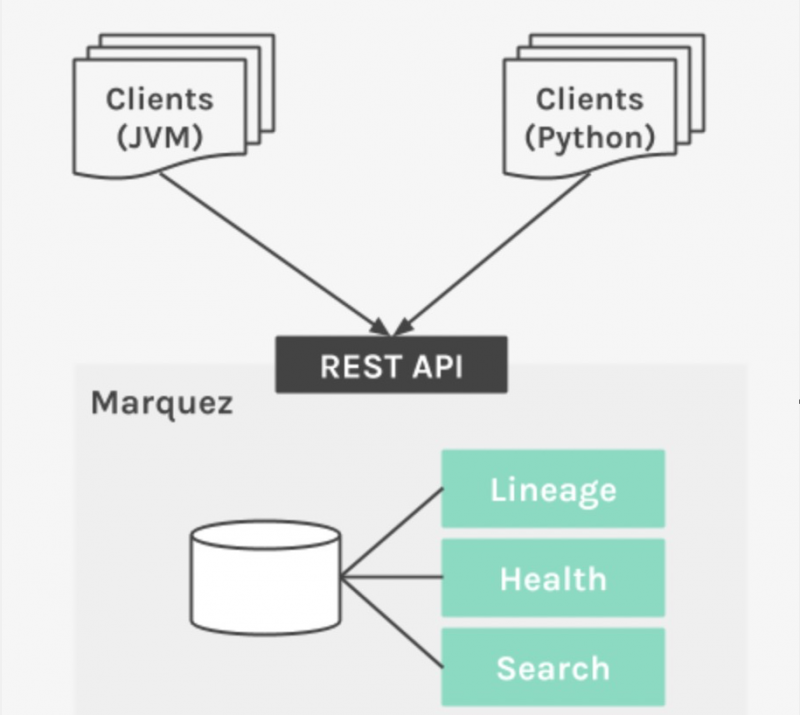
Um die Einführung zu erleichtern und die Metadatenerfassung in verschiedenen Datenverarbeitungsanwendungen zu einer zentralen Anforderung zu machen, bietet Marquez sprachspezifische Clients, die die Metadaten-API implementieren. Die erste Version unterstützt Java und Python.
Die Metadaten-API ist eine Abstraktion zur Erfassung von Informationen zur Erstellung und Nutzung von Datensätzen. Sie ist eine zustandslose Schicht mit geringer Latenz und hoher Verfügbarkeit, die für die Kapselung persistenter Metadaten und Informationen zur Sammlungsherkunft zuständig ist. Die API ermöglicht es Clients, Datensatzinformationen aus einem Metadaten-Repository zu sammeln und/oder abzurufen.
Metadaten müssen für umfangreiche explorative Abfragen über die Metadaten-Benutzeroberfläche erfasst, organisiert und gespeichert werden. Das Metadaten-Repository ist ein abstrakter Katalog von Datensatzinformationen, der von der Metadaten-API komprimiert und bereinigt wird.
Das Datenmodell von Marquez
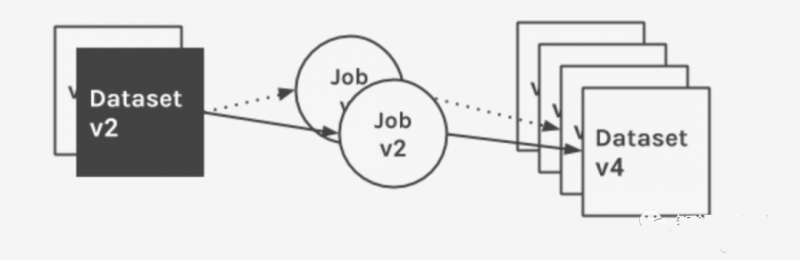
Marquez' Datenmodell legt den Schwerpunkt auf die Unveränderlichkeit und Just-in-Time-Verarbeitung von Datensätzen. Datensätze werden durch Jobausführungen generiert, wobei der Wert entscheidend ist. Jobausführungen sind mit Versionscodes verknüpft und erzeugen eine oder mehrere unveränderliche Versionsausgaben. Änderungen am Datensatz werden zu verschiedenen Zeitpunkten der Jobausführung, einschließlich des Erfolgs oder Misserfolgs der Ausführung selbst, durch Aufrufe der schlanken API aufgezeichnet.
Die folgende Abbildung zeigt die für einen bestimmten Job über mehrere Durchläufe hinweg gesammelten und katalogisierten Metadaten sowie die auf den Eingabedatensatz angewendeten Zeitreihenänderungen.
Open-Source-Tool zur Metadatenverwaltung
- Job: Der Job enthält einen Besitzer, einen eindeutigen Namen, eine Version und eine optionale Beschreibung. Ein Job definiert eine oder mehrere Versionseingaben als Abhängigkeiten und eine oder mehrere Versionsausgaben als Artefakte. Beachten Sie, dass ein Job entweder nur Eingabe- oder nur Ausgabedatasets definieren kann.
- Jobversion: Eine schreibgeschützte, unveränderliche Version des Jobs mit einem eindeutig referenzierten Link, kodiert im Speicher, um die Reproduktion des Quellcodes zu gewährleisten. Eine Jobversion verknüpft einen oder mehrere Eingabe- und Ausgabedatensätze mit einer Jobdefinition (der Datenfluss durch verschiedene Jobs ist wichtig für die Dokumentation von Herkunftsinformationen). Diese Verknüpfungen kategorisieren Quelllinks und ermöglichen einen leistungsstarken visuellen Datenfluss.
- Datensatz: Ein Datensatz verfügt über einen Besitzer, einen eindeutigen Namen, ein Schema, eine Version und eine optionale Beschreibung. Der Datensatz ist in der Datenquelle enthalten. Datenquellen können physische Datensätze in ihren physischen Quellen gruppieren. Jeder Datensatz verfügt über einen Versionszeiger zum historischen Änderungssatz, der von Marquez verwaltet wird. Wenn Datensatzänderungen an Marquez zurückgegeben werden, wird eine eindeutige Versions-ID generiert, gespeichert und auf die aktuelle Version gesetzt. Der Zeiger wird intern aktualisiert.
- Datensatzversion: Die schreibgeschützte, unveränderliche Version des Datensatzes. Jede Version kann unabhängig gelesen werden, verfügt über eine eindeutige ID und wird Änderungen am Datensatz zugeordnet, um den Zustand zu einem bestimmten Zeitpunkt zu erhalten. Die neueste Versions-ID wird nur aktualisiert, wenn Änderungen am Datensatz protokolliert werden. Um eindeutige Versions-IDs zu berechnen, wendet Marquez Versionierungsfunktionen auf eine Reihe von Eigenschaften an, die dem Datensatz der zugrunde liegenden Datenquelle entsprechen.
Abschluss
Vielen Dank für das Lesen unseres Artikels. Wir hoffen, er hilft Ihnen, Marquez besser zu verstehen: ein Open-Source-Tool zur Metadatenverwaltung. Wenn Sie mehr über Metadatenverwaltung erfahren möchten, empfehlen wir Ihnen, Folgendes zu besuchen: Gudu SQLFlow für weitere Informationen.
Als einer der die besten Datenherkunftstools Gudu SQLFlow ist heute auf dem Markt erhältlich und kann nicht nur SQL-Skriptdateien analysieren, die Datenherkunft ermitteln und eine visuelle Anzeige durchführen, sondern ermöglicht Benutzern auch, die Datenherkunft im CSV-Format bereitzustellen und eine visuelle Anzeige durchzuführen. (Veröffentlicht von Ryan am 28. Juni 2022)
Testen Sie Gudu SQLFlow Live

Wenn Ihnen dies gefällt, sehen Sie sich bitte auch unsere anderen Artikel unten an:


