Marquez : un outil de gestion des métadonnées open source
Marquez est un service de métadonnées open source pour la collecte, l'agrégation et la visualisation des métadonnées de l'écosystème de données. Il gère la consommation et la production des jeux de données, offre une visibilité globale sur l'exécution des tâches et la fréquence d'accès aux jeux de données, assure une gestion centralisée du cycle de vie des jeux de données, et bien plus encore. WeWork a publié et rendu open source Marquez.
Outil de gestion des métadonnées open source
Caractéristiques de Marquez :
1. La gestion centralisée des métadonnées prend en charge :
- Lignée de données
- Gouvernance des données
- Santé des données
- Découverte et exploration des données
2. Modèle de données précis à haute dimension :
- Emplois
- Ensembles de données
3. Collectez facilement des métadonnées via des API de métadonnées spécifiées :
- Faites attention aux données de l'ensemble de données
- Renforcer la propriété des tâches et des ensembles de données
- Fonctionnement et conception simples avec des dépendances minimales
4. L'API RESTful prend en charge l'intégration complexe avec d'autres systèmes :
- Débit d'air
- Amundsen
- Dagster
- Conçu pour promouvoir un écosystème de données sain où les membres de l'équipe d'une organisation peuvent partager de manière transparente et s'appuyer en toute sécurité sur les ensembles de données des autres en toute confiance.
Pourquoi choisir Marquez ?
Marquez prend en charge des requêtes de lignée de données hautement flexibles sur des ensembles de données complets, tout en corrélant de manière fiable et efficace les tâches et leurs dépendances (en amont et en aval) entre la génération et la consommation d'ensembles de données.
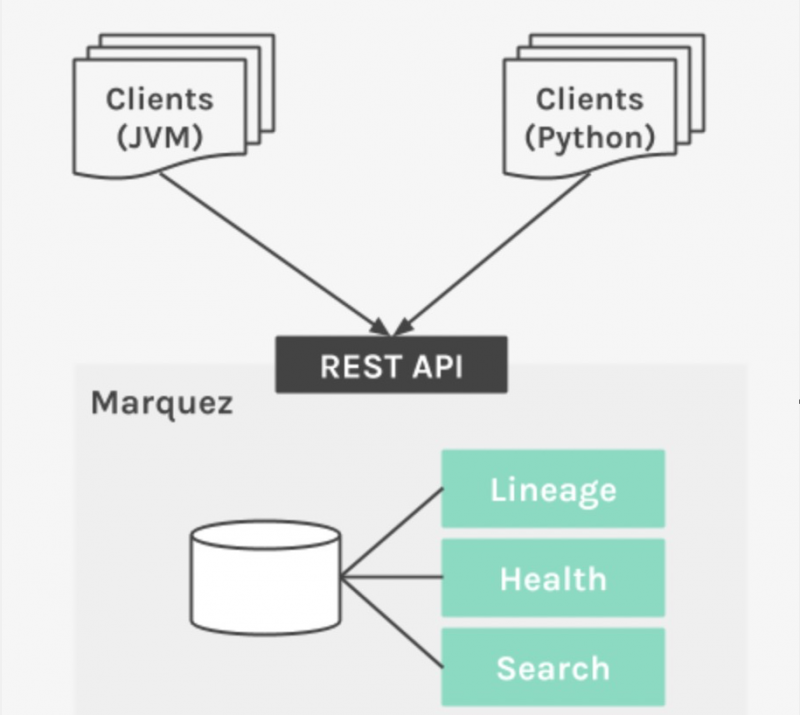
Le design de Marquez
Marquez est un système modulaire qui permet gestion des métadonnées Solution déplateforme hautement évolutive et extensible. Elle comprend les systèmes suivants :
- Référentiel de métadonnées : stocke toutes les métadonnées des tâches et des ensembles de données, y compris l'historique complet des exécutions des tâches et les statistiques au niveau des tâches (par exemple : durée totale d'exécution, durée moyenne d'exécution, réussite/échec, etc.).
- API de métadonnées : une API RESTful permet à un ensemble diversifié de clients de collecter des métadonnées autour de la production et de la consommation d'ensembles de données.
- Interface utilisateur des métadonnées : pour la découverte d’ensembles de données, la connexion de plusieurs ensembles de données et l’exploration de leur graphique de dépendance.
Outil de gestion des métadonnées open source
Pour faciliter l'adoption et permettre à différentes applications de traitement de données d'intégrer la collecte de métadonnées à leur conception, Marquez fournit des clients spécifiques au langage qui implémentent l'API de métadonnées. La version initiale prend en charge Java et Python.
L'API de métadonnées est une abstraction permettant d'enregistrer des informations sur la production et l'utilisation des jeux de données. Il s'agit d'une couche sans état à faible latence et haute disponibilité, chargée d'encapsuler les métadonnées persistantes et les informations de traçabilité des collections. L'API permet aux clients de collecter et/ou d'obtenir des informations sur les jeux de données à partir d'un référentiel de métadonnées.
Les métadonnées doivent être collectées, organisées et stockées pour des requêtes exploratoires enrichies via l'interface utilisateur des métadonnées. Le référentiel de métadonnées est un catalogue abstrait d'informations d'ensembles de données compressées et nettoyées par l'API de métadonnées.
Le modèle de données de Marquez
Le modèle de données de Marquez met l'accent sur l'immuabilité et le traitement juste-à-temps des ensembles de données. Ces ensembles sont générés par l'exécution de tâches, et leur valeur est déterminante. Les exécutions de tâches sont liées à des codes de version et produisent une ou plusieurs versions immuables. Les modifications apportées à l'ensemble de données sont enregistrées à différents moments de l'exécution de la tâche, y compris la réussite ou l'échec de l'exécution elle-même, via des appels à l'API légère.
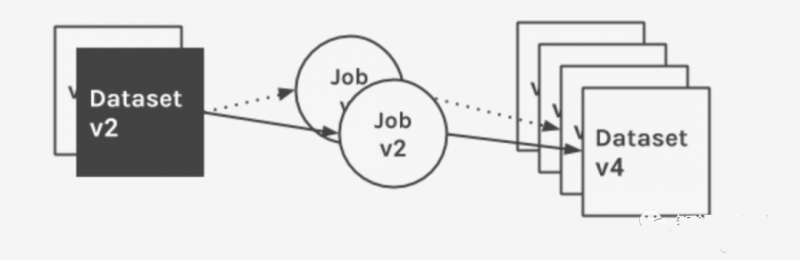
La figure ci-dessous montre les métadonnées collectées et cataloguées pour un travail donné sur plusieurs exécutions, ainsi que les modifications de séries chronologiques appliquées à son ensemble de données d'entrée.
Outil de gestion des métadonnées open source
- Tâche : La tâche contient un propriétaire, un nom unique, une version et une description facultative. Une tâche définit une ou plusieurs entrées de version comme dépendances et une ou plusieurs sorties de version comme artefacts. Notez qu'une tâche peut définir uniquement des jeux de données d'entrée ou de sortie.
- Version de tâche : une version immuable en lecture seule de la tâche, avec un lien référencé de manière unique, encodée dans le stockage pour garantir la reproduction du code source. Une version de tâche associe un ou plusieurs jeux de données d'entrée et de sortie à une définition de tâche (le flux de données entre les différentes tâches est important pour documenter les informations de lignage). Ces associations catégorisent les liens sources et fournissent un flux de données visuel puissant.
- Ensemble de données : un ensemble de données possède un propriétaire, un nom unique, un schéma, une version et une description facultative. Il est contenu dans la source de données. Ces sources peuvent regrouper des ensembles de données physiques. Chaque ensemble de données possède un pointeur de version vers l'historique des modifications, géré par Marquez. Lorsque les modifications de l'ensemble de données sont validées dans Marquez, un identifiant de version unique est généré, stocké, puis défini sur la version actuelle, et le pointeur est mis à jour en interne.
- Version du jeu de données : version immuable en lecture seule du jeu de données. Chaque version est lisible indépendamment, possède un identifiant unique et correspond aux modifications apportées au jeu de données afin de préserver son état à un instant T. L'identifiant de la dernière version n'est mis à jour que lorsque les modifications du jeu de données sont enregistrées. Pour calculer des identifiants de version distincts, Marquez applique des fonctionnalités de gestion des versions à un ensemble de propriétés correspondant au jeu de données de la source de données sous-jacente.
Conclusion
Merci d'avoir lu notre article et nous espérons qu'il vous aidera à mieux comprendre Marquez : un outil open source de gestion des métadonnées. Pour en savoir plus sur la gestion des métadonnées, nous vous conseillons de consulter notre site. Gudu SQLFlow pour plus d'informations.
En tant que l'un des meilleurs outils de lignage de données Disponible sur le marché aujourd'hui, Gudu SQLFlow peut non seulement analyser les fichiers de script SQL, obtenir la lignée des données et effectuer un affichage visuel, mais également permettre aux utilisateurs de fournir la lignée des données au format CSV et d'effectuer un affichage visuel. (Publié par Ryan le 28 juin 2022)
Essayez Gudu SQLFlow Live

Si vous aimez lire ceci, alors n'hésitez pas à explorer nos autres articles ci-dessous :


