Marquez: una herramienta de gestión de metadatos de código abierto
Marquez es un servicio de metadatos de código abierto para la recopilación, agregación y visualización de metadatos del ecosistema de datos. Gestiona el consumo y la producción de conjuntos de datos, proporciona visibilidad global del tiempo de ejecución de los trabajos y la frecuencia de acceso a los conjuntos de datos, proporciona una gestión centralizada del ciclo de vida de los conjuntos de datos y mucho más. WeWork lanzó Marquez de código abierto.
Herramienta de gestión de metadatos de código abierto
Características de Márquez:
1. La gestión centralizada de metadatos admite:
- Linaje de datos
- Gobernanza de datos
- Salud de los datos
- Descubrimiento y exploración de datos
2. Modelo de datos preciso de alta dimensión:
- Empleos
- Conjuntos de datos
3. Recopile metadatos fácilmente a través de API de metadatos específicas:
- Preste atención a los datos del conjunto de datos
- Reforzar la propiedad del trabajo y del conjunto de datos
- Operación y diseño simples con dependencias mínimas
4. La API RESTful admite una integración compleja con otros sistemas:
- Flujo de aire
- Amundsen
- Dagster
- Diseñado para promover un ecosistema de datos saludable donde los miembros del equipo de una organización puedan compartir sin problemas y confiar de forma segura en los conjuntos de datos de los demás.
¿Por qué elegir Márquez?
Marquez admite consultas de linaje de datos altamente flexibles en conjuntos de datos completos, al mismo tiempo que correlaciona de manera confiable y eficiente los trabajos y sus dependencias (ascendentes y descendentes) entre la generación y el consumo de conjuntos de datos.
El diseño de Márquez
Marquez es un sistema modular que permite gestión de metadatos Como una solución desplataforma altamente escalable y extensible. Consta de los siguientes sistemas:
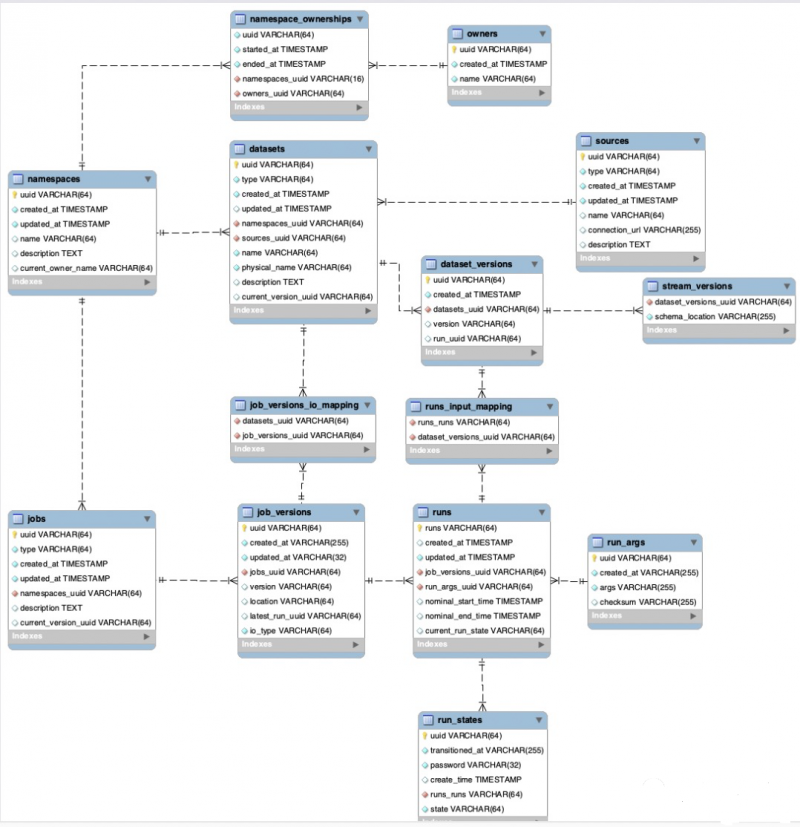
- Repositorio de metadatos: almacena todos los metadatos de trabajos y conjuntos de datos, incluido el historial completo de ejecuciones de trabajos y las estadísticas a nivel de trabajo (por ejemplo: tiempo total de ejecución, tiempo de ejecución promedio, éxito/fracaso, etc.).
- API de metadatos: una API RESTful permite que un conjunto diverso de clientes recopilen metadatos sobre la producción y el consumo de conjuntos de datos.
- Interfaz de usuario de metadatos: para descubrir conjuntos de datos, conectar múltiples conjuntos de datos y explorar su gráfico de dependencia.
Herramienta de gestión de metadatos de código abierto
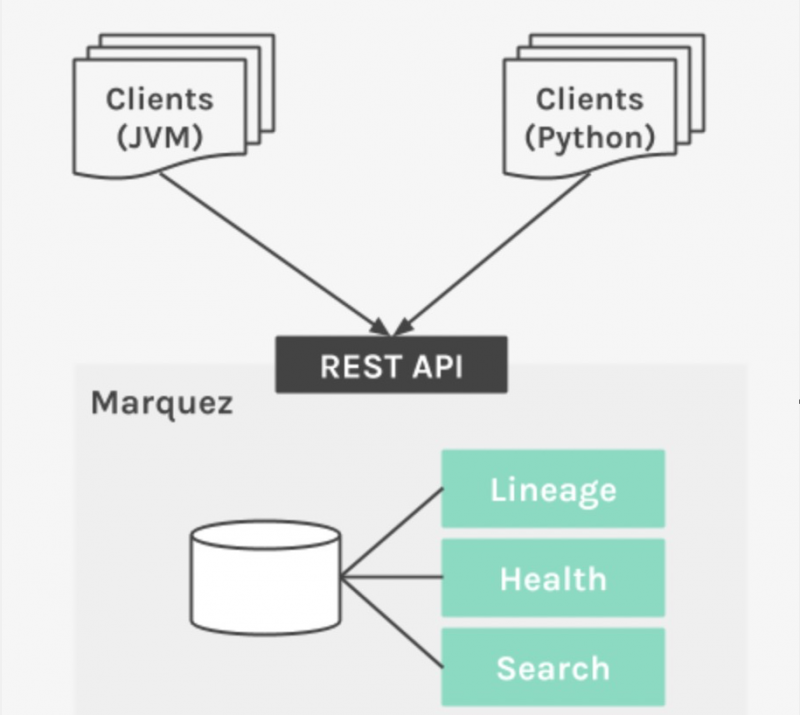
Para facilitar la adopción y permitir que la recopilación de metadatos sea un requisito fundamental en el diseño de diferentes aplicaciones de procesamiento de datos, Marquez proporciona clientes específicos para cada lenguaje que implementan la API de metadatos. Como parte de la versión inicial, es compatible con Java y Python.
La API de metadatos es una abstracción para registrar información sobre la producción y el uso de conjuntos de datos. Es una capa sin estado de baja latencia y alta disponibilidad, responsable de encapsular metadatos persistentes e información de linaje de colecciones. La API permite a los clientes recopilar u obtener información de conjuntos de datos de un repositorio de metadatos.
Es necesario recopilar, organizar y almacenar metadatos para realizar consultas exploratorias exhaustivas mediante la interfaz de metadatos. El repositorio de metadatos es un catálogo abstracto de información de conjuntos de datos, comprimido y depurado por la API de metadatos.
El modelo de datos de Márquez
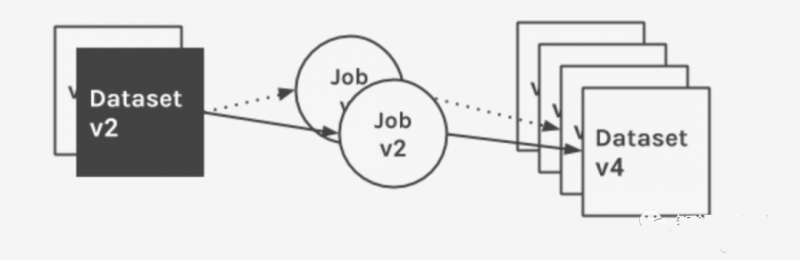
El modelo de datos de Márquez enfatiza la inmutabilidad y el procesamiento justo a tiempo de los conjuntos de datos. Los conjuntos de datos se generan mediante ejecuciones de trabajos, y su valor es importante. Las ejecuciones de trabajos se vinculan con códigos de versión y producen una o más salidas de versión inmutables. Los cambios en el conjunto de datos se registran en varios puntos de la ejecución del trabajo, incluyendo el éxito o el fracaso de la ejecución, mediante llamadas a la API ligera.
La siguiente figura muestra los metadatos recopilados y catalogados para un trabajo determinado en múltiples ejecuciones, y los cambios de series de tiempo aplicados a su conjunto de datos de entrada.
Herramienta de gestión de metadatos de código abierto
- Trabajo: El trabajo contiene un propietario, un nombre único, una versión y una descripción opcional. Un trabajo define una o más entradas de versión como dependencias y una o más salidas de versión como artefactos. Tenga en cuenta que un trabajo puede definir solo conjuntos de datos de entrada o solo conjuntos de datos de salida.
- Versión del trabajo: Una versión inmutable de solo lectura del trabajo, con un enlace de referencia única, codificada en el almacenamiento para garantizar la reproducción del código fuente. Una versión del trabajo asocia uno o más conjuntos de datos de entrada y salida a una definición de trabajo (el flujo de datos entre varios trabajos es importante para documentar la información de linaje). Estas asociaciones categorizan los enlaces de origen y proporcionan un flujo visual de datos eficaz.
- Conjunto de datos: Un conjunto de datos tiene un propietario, un nombre único, un esquema, una versión y una descripción opcional. El conjunto de datos se encuentra en la fuente de datos. Las fuentes de datos pueden agrupar conjuntos de datos físicos en sus fuentes físicas. Cada conjunto de datos tiene un puntero de versión al conjunto de cambios histórico, mantenido por Marquez. Cuando los cambios del conjunto de datos se confirman en Marquez, se genera un ID de versión único, se almacena y se establece en la versión actual. El puntero se actualiza internamente.
- Versión del conjunto de datos: La versión inmutable de solo lectura del conjunto de datos. Cada versión se puede leer de forma independiente, tiene un ID único y se asigna a los cambios del conjunto de datos para preservar su estado en un momento específico. El ID de la última versión solo se actualiza cuando se registran los cambios en el conjunto de datos. Para calcular los distintos ID de versión, Marquez aplica funciones de control de versiones a un conjunto de propiedades correspondientes al conjunto de datos de la fuente de datos subyacente.
Conclusión
Gracias por leer nuestro artículo. Esperamos que le ayude a comprender mejor Marquez: una herramienta de gestión de metadatos de código abierto. Si desea obtener más información sobre la gestión de metadatos, le recomendamos visitar Flujo de SQL de Gudu Para más información.
Como uno de los Las mejores herramientas de linaje de datos Disponible actualmente en el mercado, Gudu SQLFlow no solo puede analizar archivos de script SQL, obtener linaje de datos y realizar una visualización, sino que también permite a los usuarios proporcionar linaje de datos en formato CSV y realizar una visualización. (Publicado por Ryan el 28 de junio de 2022)
Pruebe Gudu SQLFlow Live

Si te gusta leer esto, explora nuestros otros artículos a continuación:


