Marquez: Uma ferramenta de gerenciamento de metadados de código aberto
Marquez é um serviço de metadados de código aberto para coleta, agregação e visualização de metadados do ecossistema de dados. Ele mantém o consumo e a produção do conjunto de dados, fornece visibilidade global do tempo de execução do trabalho e da frequência de acesso ao conjunto de dados, fornece gerenciamento centralizado do ciclo de vida do conjunto de dados e muito mais. A WeWork lançou e tornou o Marquez de código aberto.
Ferramenta de gerenciamento de metadados de código aberto
Características do Márquez:
1. O gerenciamento centralizado de metadados oferece suporte a:
- Linhagem de dados
- Governança de dados
- Saúde dos dados
- Descoberta e exploração de dados
2. Modelo de dados preciso de alta dimensão:
- Empregos
- Conjuntos de dados
3. Colete metadados facilmente por meio de APIs de metadados especificadas:
- Preste atenção aos dados do conjunto de dados
- Reforce a propriedade do trabalho e do conjunto de dados
- Operação e design simples com dependências mínimas
4. A API RESTful suporta integração complexa com outros sistemas:
- Fluxo de ar
- Amundsen
- Punhal
- Projetado para promover um ecossistema de dados saudável, onde os membros da equipe de uma organização podem compartilhar facilmente e confiar com segurança nos conjuntos de dados uns dos outros.
Por que escolher Márquez?
O Marquez oferece suporte a consultas de linhagem de dados altamente flexíveis em conjuntos de dados completos, ao mesmo tempo em que correlaciona de forma confiável e eficiente os trabalhos e suas dependências (upstream e downstream) entre a geração e o consumo de conjuntos de dados.
O Design de Márquez
Marquez é um sistema modular que permite gerenciamento de metadados como uma solução de-plataforma altamente escalável e extensível. Consiste nos seguintes sistemas:
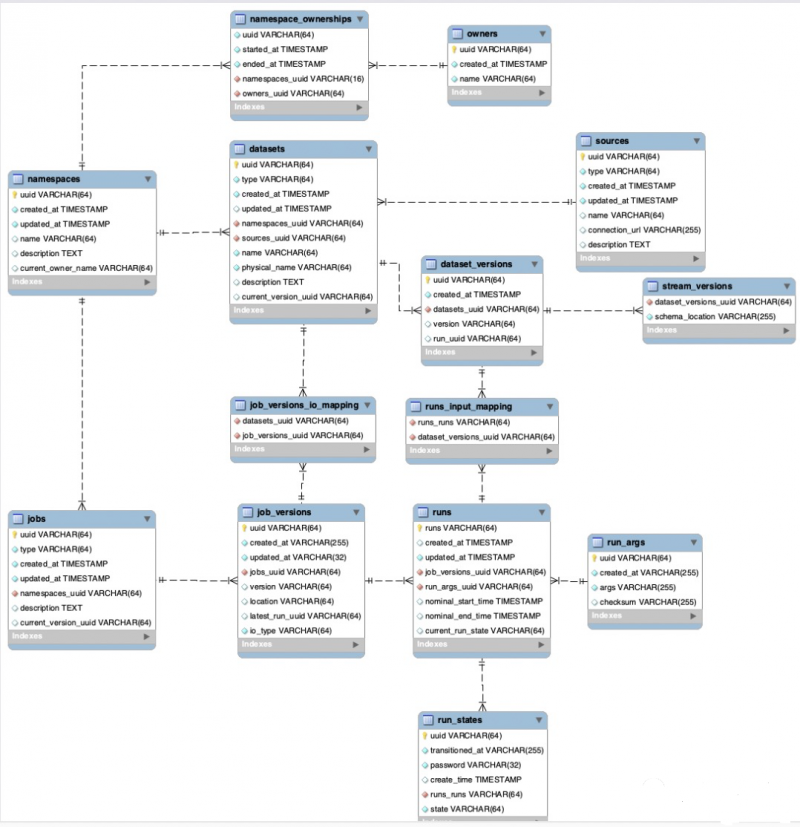
- Repositório de metadados: armazena todos os metadados de trabalhos e conjuntos de dados, incluindo histórico completo de execuções de trabalhos e estatísticas em nível de trabalho (por exemplo: tempo total de execução, tempo médio de execução, sucesso/falha, etc.).
- API de metadados: uma API RESTful permite que um conjunto diversificado de clientes colete metadados sobre a produção e o consumo de conjuntos de dados.
- Interface de metadados: para descoberta de conjuntos de dados, conexão de vários conjuntos de dados e exploração de seus gráficos de dependência.
Ferramenta de gerenciamento de metadados de código aberto
Para facilitar a adoção e permitir que diferentes aplicativos de processamento de dados tenham a coleta de metadados como um requisito central de seu design, a Marquez fornece clientes específicos de linguagem que implementam a API de metadados. Como parte do lançamento inicial, ele oferece suporte a Java e Python.
A API de metadados é uma abstração para registrar informações sobre a produção e o uso de conjuntos de dados. É uma camada sem estado de baixa latência e alta disponibilidade responsável por encapsular metadados persistentes e informações de linhagem de coleção. A API permite que os clientes coletem e/ou obtenham informações de conjuntos de dados de um repositório de metadados.
Metadados precisam ser coletados, organizados e armazenados para consultas exploratórias ricas por meio da UI de metadados. O repositório de metadados é um catálogo abstrato de informações de conjuntos de dados compactadas e limpas pela API de metadados.
O Modelo de Dados de Marquez
O modelo de dados de Marquez enfatiza a imutabilidade e o processamento just-in-time de conjuntos de dados. Os conjuntos de dados são gerados por execuções de trabalho, e o valor importa. As execuções de trabalho são vinculadas a códigos de versão e produzem uma ou mais saídas de versão imutáveis. As alterações no conjunto de dados são registradas em vários pontos da execução do trabalho, incluindo o sucesso ou a falha da execução em si, por meio de chamadas para a API leve.
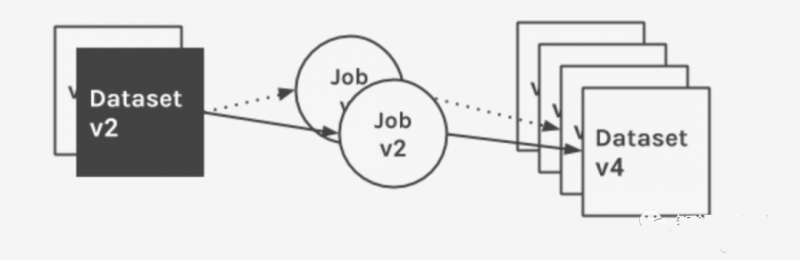
A figura abaixo mostra os metadados coletados e catalogados para um determinado trabalho em várias execuções e as alterações de séries temporais aplicadas ao seu conjunto de dados de entrada.
Ferramenta de gerenciamento de metadados de código aberto
- Job: O job contém um proprietário, nome exclusivo, versão e uma descrição opcional. Um job define uma ou mais entradas de versão como dependências e uma ou mais saídas de versão como artefatos. Observe que um job pode definir apenas conjuntos de dados de entrada ou apenas conjuntos de dados de saída.
- Versão do trabalho: Uma versão imutável somente leitura do trabalho, com um link referenciado exclusivamente, codificado no armazenamento para garantir a reprodução do código-fonte. Uma versão do trabalho associa um ou mais conjuntos de dados de entrada e saída a uma definição de trabalho (o fluxo de dados por vários trabalhos é importante para documentar informações de linhagem). Essas associações categorizam links de origem e fornecem um fluxo visual poderoso de dados.
- Conjunto de dados: Um conjunto de dados tem um proprietário, nome exclusivo, esquema, versão e uma descrição opcional. O conjunto de dados está contido na fonte de dados. As fontes de dados podem agrupar conjuntos de dados físicos em suas fontes físicas. Cada conjunto de dados tem um ponteiro de versão para o conjunto de alterações histórico, mantido pelo Marquez. Quando as alterações do conjunto de dados são confirmadas de volta para o Marquez, um ID de versão exclusivo é gerado, armazenado e, em seguida, definido para a versão atual, e o ponteiro é atualizado internamente.
- Versão do conjunto de dados: a versão imutável somente leitura do conjunto de dados. Cada versão pode ser lida de forma independente, tem um ID exclusivo e mapeia para alterações no conjunto de dados para preservar seu estado em um ponto específico no tempo. O ID da versão mais recente é atualizado somente quando as alterações no conjunto de dados são registradas. Para calcular IDs de versão distintos, o Marquez aplica recursos de controle de versão a um conjunto de propriedades correspondentes ao conjunto de dados da fonte de dados subjacente.
Conclusão
Obrigado por ler nosso artigo e esperamos que ele possa ajudá-lo a ter um melhor entendimento do Marquez: uma ferramenta de gerenciamento de metadados de código aberto. Se você quiser saber mais sobre gerenciamento de metadados, gostaríamos de aconselhá-lo a visitar Gudu SQLFlow para maiores informações.
Como um dos melhores ferramentas de linhagem de dados disponível no mercado hoje, o Gudu SQLFlow não só pode analisar arquivos de script SQL, obter linhagem de dados e executar exibição visual, mas também permitir que os usuários forneçam linhagem de dados em formato CSV e executem exibição visual. (Publicado por Ryan em 28 de junho de 2022)
Experimente o Gudu SQLFlow Live

Se você gosta de ler isso, explore nossos outros artigos abaixo:


