Evolução da Arquitetura de Metadados
Gerenciamento de metadados é a fundação e fonte da governança de dados sistema. Em diferentes estágios de desenvolvimento tecnológico, seu status e papel na governança de dados corporativos são muito diferentes. Hoje, os dados têm as características de multifonte, heterogeneidade e diferença de valor, e essas características são aceleradas e amplificadas no processo de crescimento louco de dados. Além disso, depois que o poder de computação das empresas geralmente aumentou significativamente, há uma forte expectativa de que os dados sejam minerados de forma mais profunda para exercer maior valor.
Como equipe de suporte de dados corporativos, a pergunta que mais ouvimos no dia a dia é "como obter o conjunto de dados correto". Percebemos que, embora tenhamos construído armazenamento de dados altamente escalável, computação em tempo real e muito mais, nossas equipes ainda estão perdendo tempo encontrando os conjuntos de dados certos para desenvolver e analisar. Ou seja, ainda não temos o gerenciamento de ativos de dados. Na verdade, há muitas empresas que oferecem soluções de código aberto para os problemas acima, ou seja, ferramentas de descoberta de dados e gerenciamento de metadados.
No entanto, por ser limitado pelas necessidades de desenvolvimento de negócios e tecnologia de várias empresas em vários estágios, a seleção de funções, aplicações e direções de foco para a construção de plataformas de gerenciamento relevantes por empresas geralmente varia amplamente. Este artigo tem como objetivo apresentar a evolução arquitetônica de ferramentas de gerenciamento de metadados.
Simplificando, o gerenciamento de metadados é a organização e o gerenciamento eficientes de ativos de dados usando metadados. Ele também pode ajudar profissionais de dados a coletar, organizar, acessar e enriquecer metadados, e dar suporte a aplicativos de camada superior, como mapas de dados, especificação de dados, controle de custos, inspeção de qualidade e auditoria de segurança.
Trinta anos atrás, um ativo de dados poderia ser apenas uma tabela em um banco de dados Oracle. No entanto, na empresa moderna, temos uma variedade desconcertante de diferentes tipos de ativos de dados. Pode ser uma tabela de banco de dados relacional, um objeto em um banco de dados não relacional, um pedaço de dados de streaming em tempo real, um indicador, um retrato ou um mostrador ou um painel em uma ferramenta de BI.
Um sistema moderno de gerenciamento de metadados deve cobrir todos os tipos de ativos de dados e ser capaz de ajudar os trabalhadores de dados a fazer melhor uso dos ativos de dados relacionados. Portanto, as principais funções do sistema de gerenciamento de metadados aplicáveis hoje são as seguintes:
- Pesquisa e descoberta: tabelas de dados, campos, tags, informações de uso;
- Controle de acesso: grupos de controle de acesso, usuários, políticas;
- Linhagem de dados: execução de pipeline, consulta;
- Conformidade: classificação dos tipos de anotação de privacidade/conformidade de dados;
- Gerenciamento de dados: configuração da fonte de dados, configuração de ingestão, configuração de retenção, política de limpeza de dados;
- Interpretabilidade e reprodutibilidade da IA: definição de recursos, definição de modelo, execução de treinamento, declaração de problema;
- Manipulação de dados: execução de pipeline, partição de dados processados, estatísticas de dados;
- Qualidade dos dados: definição de regra de qualidade de dados, resultado de execução de regra, estatísticas de dados.
Evolução da Arquitetura de Metadados:
O primeira geração arquitetura de metadados é geralmente baseado em extração. Metadados são obtidos conectando e consultando fontes de dados (Hive, Kafka, etc.), e apenas serviços de armazenamento e consulta externos são necessários. Geralmente é um front-end monolítico clássico que se conecta ao armazenamento primário para consultas (geralmente MySQL/Postgres), um índice de pesquisa (geralmente Elasticsearch) que atende consultas de pesquisa quando a consulta atinge o limite de “consulta recursiva” de um banco de dados relacional, pode ser atualizado para usar um banco de dados de gráfico (geralmente Neo4j) como o índice de consulta.
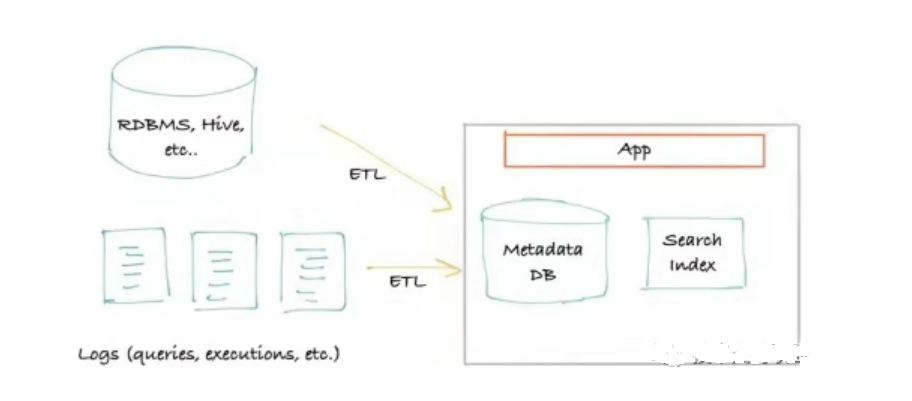
Arquitetura de Metadados
As vantagens dessa arquitetura de metadados são óbvias: a arquitetura é simples e pode ser construída rapidamente com apenas armazenamento e um mecanismo de busca, com alta eficiência e baixo custo. Mas as deficiências também são óbvias: ela tem um impacto considerável no desempenho da fonte de dados e há muitos requisitos para o tempo de extração, frequência e carga. Além disso, como os requisitos de tempo real estão ficando cada vez maiores, essa arquitetura de metadados está se tornando cada vez mais inaplicável.
O produto de código aberto Amundsen tem uma arquitetura de primeira geração, mas se concentra na função de obter classificação de pesquisa, o que é muito poderoso.
O segunda geração arquitetura de metadados é uma arquitetura de aplicativo de três camadas baseada em divisão de serviços. Essa arquitetura divide o aplicativo monolítico de serviços de metadados. O serviço fornece uma API que permite que metadados sejam gravados no sistema usando um mecanismo push, e uma API de leitura de metadados para programas que precisam ler metadados programaticamente.
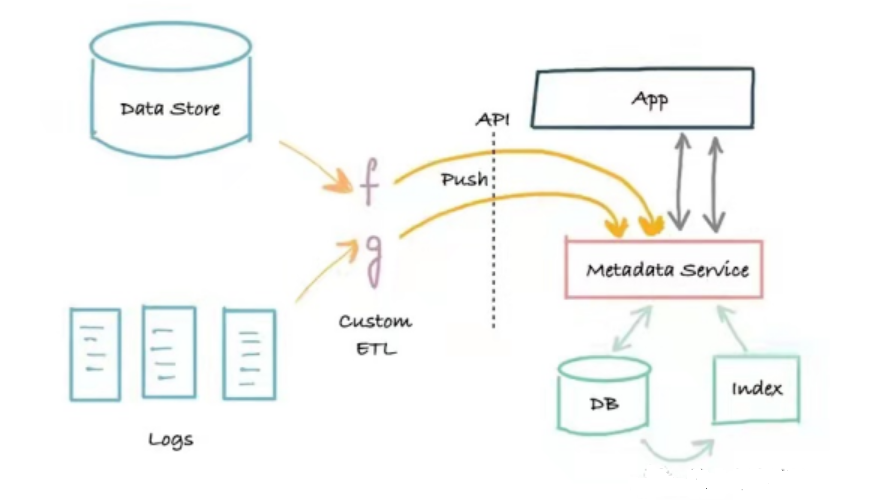
Arquitetura de Metadados
A vantagem dessa arquitetura é que ela é implementada com base no método push, que constrói uma ponte entre o produtor de metadados e o serviço de metadados, e resolve o problema em tempo real. A desvantagem é que não há logs. Quando algo dá errado, pode ser difícil inicializar (recriar) ou corrigir índices de pesquisa e gráfico de forma confiável. Os sistemas de metadados de segunda geração podem frequentemente ser um portal confiável de pesquisa e descoberta para os ativos de dados de uma empresa, abordando as principais necessidades dos trabalhadores de dados, e Marquez tem uma arquitetura de metadados de segunda geração.
O arquitetura de metadados de terceira geração é uma arquitetura de gerenciamento de metadados baseada em eventos, que é baseada em log push + desacoplamento de modelo. Os usuários podem interagir com o banco de dados de metadados de diferentes maneiras, de acordo com suas necessidades, e podem definir modelos de metadados estendidos.
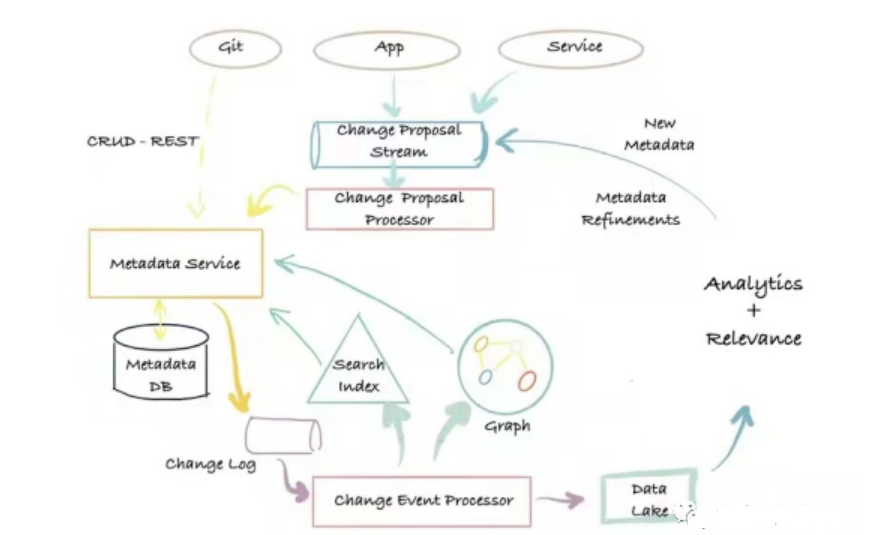
Arquitetura de Metadados
Suas principais vantagens são: flexibilidade, alta escalabilidade, pesquisa de baixa latência, capacidade de executar pesquisas de texto completo e classificação em atributos de metadados, consultas de gráfico que suportam relacionamentos de metadados e recursos completos de varredura e análise. A desvantagem é: há muitos componentes dependentes e o custo de operação e manutenção é alto. Os sistemas representativos da arquitetura de metadados de terceira geração são Altas e DataHub.
Uma representação visual simples do cenário atual da plataforma de gerenciamento de metadados (incluindo não-open source):
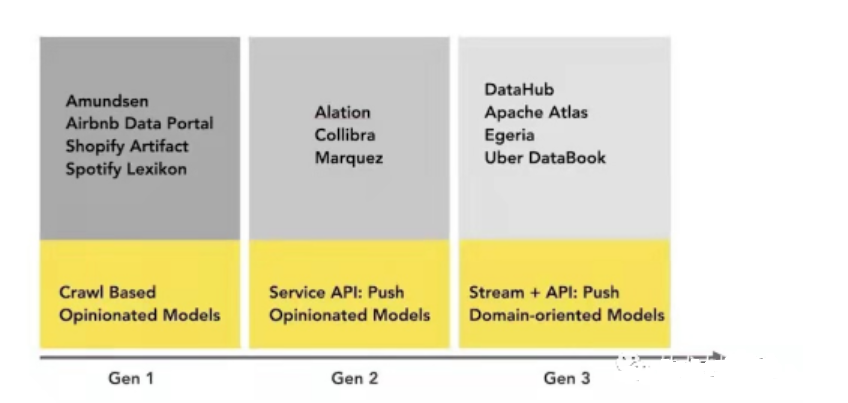
Conclusão
Obrigado por ler nosso artigo e esperamos que ele possa ajudá-lo a ter um melhor entendimento da evolução da arquitetura de metadados. Se você quiser aprender mais sobre metadados, gostaríamos de aconselhá-lo a visitar Gudu SQLFlow para maiores informações.
Como um dos melhores ferramentas de linhagem de dados disponível no mercado hoje, o Gudu SQLFlow não só pode analisar arquivos de script SQL, obter linhagem de dados e executar exibição visual, mas também permitir que os usuários forneçam linhagem de dados em formato CSV e executem exibição visual. (Publicado por Ryan em 29 de junho de 2022)
Experimente o Gudu SQLFlow Live

Se você gosta de ler isso, explore nossos outros artigos abaixo:


