Linhagem de dados do Amazon Redshift | Gudu SQLFlow
No seu ambiente de warehouse da Amazon, use Espectro Redshift da Amazon para consultar dados diretamente de arquivos no Amazon S3, salvar dados em bancos de dados Redshift e usar ferramentas de Business Intelligence como Tableau, PowerBI, Looker, Qlik, Superset para gerar relatórios a partir dos dados. Os dados se originam do seu sistema de origem empresarial e chegam ao Amazon S3, usando então uma ferramenta ETL como DBT para transferi-los e armazená-los no Redshift Database para usos posteriores.

Linhagem de dados do Amazon Redshift
Para ter uma visão geral do fluxo de dados em seu sistema de warehouse da Amazon, você precisa de um ferramenta de linhagem de dados para ajudar você a entender como os dados chegaram a um local específico, bem como as etapas intermediárias e transformações que acontecem à medida que os dados se movem pelo sistema de negócios.
Uma maneira de obter a linhagem de dados automaticamente do ambiente de warehouse da Amazon é analisar todas as consultas SQL usadas durante o carregamento, transformação e análise de dados. A boa notícia é que todas essas instruções SQL são armazenadas em o log de atividades do usuário Redshift e Gudu Fluxo SQL pode analisar esses arquivos de log para descobrir a linhagem de dados automaticamente.
Registro de atividades do usuário Redshift
O log de atividade do usuário é útil principalmente para fins de solução de problemas e aqui o usamos para a descoberta da linhagem de dados. Ele rastreia informações sobre os tipos de consultas que tanto os usuários quanto o sistema realizam no banco de dados.
Registra cada consulta antes de executá-la no banco de dados.
| Nome da coluna | Descrição |
|---|---|
| tempo recorde | Hora em que o evento ocorreu. |
| banco de dados | Nome do banco de dados. |
| usuário | Nome de usuário. |
| pid | ID do processo associado à declaração. |
| ID do usuário | ID do usuário. |
| xid | ID da transação. |
| consulta | Um prefixo de LOG: seguido pelo texto da consulta, incluindo novas linhas. |
por favor, verifique este artigo para ver como habilitar o registro.
Exemplo de log de auditoria de atividade do usuário do Amazon Redshift
'2018-05-21T06:00:09Z UTC [ db=prod_sales user=duc pid=99753 userid=95 xid=6728324 ]' LOG: criar tabela SumoProdbackUp.organization como (selecionar * de SumoProd.simpleuser) '2018-05-21T06:00:09Z UTC [ db=vendor user=ankit pid=36616 userid=53 xid=2956702 ]' LOG: EXCLUIR DE SumoProd.employee ONDE id = 38; '2018-05-21T06:20:09Z UTC [ db=dev user=himanshu pid=64458 userid=35 xid=5143208 ]' LOG: remover usuário testuser3
Análise automática de linhagem de dados
Gudu SQLFlow é uma ferramenta que automatizou a análise de linhagem de dados SQL em ambientes de Bancos de Dados, ETL, Business Intelligence, Nuvem e Hadoop, analisando o SQL Script e o procedimento armazenado. Ele também pode analisar os arquivos de log de atividade do usuário Redshift para descobrir a linhagem de dados e descrever todo o movimento de dados graficamente.
Aqui está uma parte de uma imagem de linhagem de dados que foi gerada após a análise dos arquivos de log de atividades do usuário do Amazon Redshift:
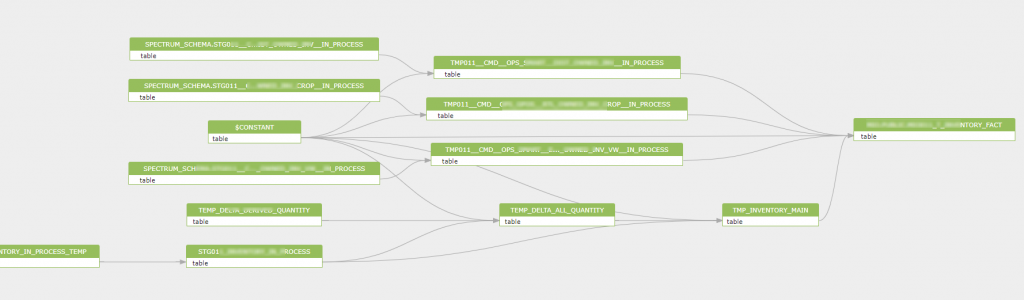
Conclusão
Obrigado por ler nosso artigo e esperamos que ele possa ajudá-lo a ter uma melhor compreensão de Linhagem de dados do Amazon Redshift. Se você quiser saber mais sobre Linhagem de dados do Amazon Redshift, gostaríamos de aconselhá-lo a visitar o nosso site Gudu SQLFlow para mais informações. Gudu SQLFlow, como uma ferramenta de análise de linhagem de dados, pode não apenas analisar arquivos de script SQL, obter linhagem de dados e executar exibição visual, mas também permitir que os usuários forneçam linhagem de dados em formato CSV e executem exibição visual. Obrigado novamente! (Editado por Ryan em 26 de abril de 2022)
Experimente o Gudu SQLFlow Live

Se você gosta de ler isso, explore nossos outros artigos abaixo:

