Unterschied zwischen Data Mining und Data Warehousing
Datengewinnung Und Data Warehousing sind zwei wesentliche Prozesse für jedes Unternehmen, das auf globaler oder nationaler Ebene Anerkennung erlangen möchte. Beide Technologien helfen, Datenbetrug zu verhindern und Managementstatistiken und Rankings zu verbessern. Data Mining wird eingesetzt, um signifikante Muster zu erkennen, indem die während der Data-Warehousing-Phase gesammelten Daten genutzt werden. Obwohl Data Mining und Data Warehousing beide als Teil von Datenanalyse, sie funktionieren auf unterschiedliche Weise. In diesem Artikel untersuchen wir die Unterschiede zwischen den beiden und ob das eine ohne das andere existieren kann.

Unterschied zwischen Data Mining und Data Warehousing
Datengewinnung
Data Mining, also die Analyse großer Datensätze und die Erkennung von Mustern, ist ein Teilgebiet der Datenwissenschaft und wird in verschiedenen Bereichen wie Marketing, Finanzen und Ingenieurwesen eingesetzt. Data Mining kann manuell oder mithilfe automatisierter Systeme erfolgen. Open-Source-Software-Frameworks wie Hadoop ermöglichen die Speicherung, den Zugriff und die Verwaltung Ihrer Daten.
Data Mining nutzt Software für künstliche Intelligenz, um große Datenmengen zu analysieren. Mithilfe von Algorithmen des maschinellen Lernens werden Verkaufsdaten im Zeitverlauf analysiert, um Muster in den Daten zu erkennen. Auf Grundlage dieser Muster werden dann Vorhersagen über zukünftige Ereignisse getroffen.
Trotz der Komplexität von Machine-Learning-Algorithmen ist die Modellbereitstellung im Vergleich zum Algorithmustraining ein einfacher Prozess. Die Bereitstellung eines Modells umfasst beispielsweise die Konvertierung des Modells in ein anderes Format und das Laden auf die vorgesehene Maschine.
Viele gängige Machine-Learning-Algorithmen nutzen Transferlernen. Das bedeutet, dass Sie das Modell auf jedem System bereitstellen können. Durch kontinuierliche Bereitstellung kann das Gerät das Schema und sein Schema für jedes neue Schema neu erlernen.
Immer mehr Branchen suchen nach Möglichkeiten, Data-Mining-Funktionen zu nutzen. Data Mining umfasst drei Phasen: Datenaufbereitung, Modellerstellung, Validierung und Bereitstellung. Diese Funktionen ermöglichen das Sammeln und Analysieren von Informationen, um bessere Entscheidungen und Strategien zu treffen.
Manche Unternehmen erfassen und analysieren Benutzerinformationen, während andere Data-Mining-Funktionen zur Trendanalyse nutzen. Manche Unternehmen nutzen beispielsweise Benutzerdaten, um zu bestimmen, welche Produkte sie verkaufen sollten.
Durch Datenanalyse und Trendanalyse können sie erkennen, welche Produkte beliebt sind, und mehr davon produzieren, um sicherzustellen, dass sie den Kundenbedürfnissen entsprechen. Data-Mining-Funktionen eignen sich hervorragend zum Sammeln und Analysieren von Daten.
Data Warehousing
Ein Data Warehouse speichert Daten an einem Ort, sodass mehrere Personen darauf zugreifen, sie teilen und nutzen können. Das Data Warehouse basiert auf einem relationalen Datenbankmanagementsystem (RDBMS). Es strukturiert Daten in Tabellen und erleichtert Benutzern die Abfrage.
In einem Data Warehouse werden alle relevanten Geschäftsinformationen Ihres Unternehmens gespeichert. Beispielsweise Name und Adresse des Kunden, Produktinformationen zu jeder Bestellung oder monatliche Umsatzzahlen.
Ein gutes Beispiel ist die Google Search Console, mit der Sie die Leistung Ihrer Website anhand mehrerer Dimensionen analysieren können. Zu diesen Dimensionen gehören Traffic-Quellen, Nutzerverhalten und mehr.
Das RDBMS verfolgt alle Änderungen an jeder Tabellenzeile. Wenn Sie Änderungen vornehmen oder neue Datensätze in einer der Tabellen einfügen, werden diese Änderungen automatisch in allen anderen Kopien übernommen.
Es gibt drei Haupttypen von Data Warehouses, jeder mit seinen eigenen, spezifischen Funktionen:
- Vertriebs- und Marketingabteilungen nutzen Data Marts um Daten aus Quellen wie Kunden und Rezensenten zu sammeln.
- Ein Enterprise Data Warehouse ist eine zentrale Datenbank, die alle Abteilungen einer Organisation vereint. Sie bildet das Herzstück von Entscheidungsunterstützungssystemen.
- Der operative Datenspeicher enthält Benutzerdaten und wird häufig aktualisiert. Sie arbeiten für Mitarbeiter.
Unterschied zwischen Data Mining und Data Warehousing
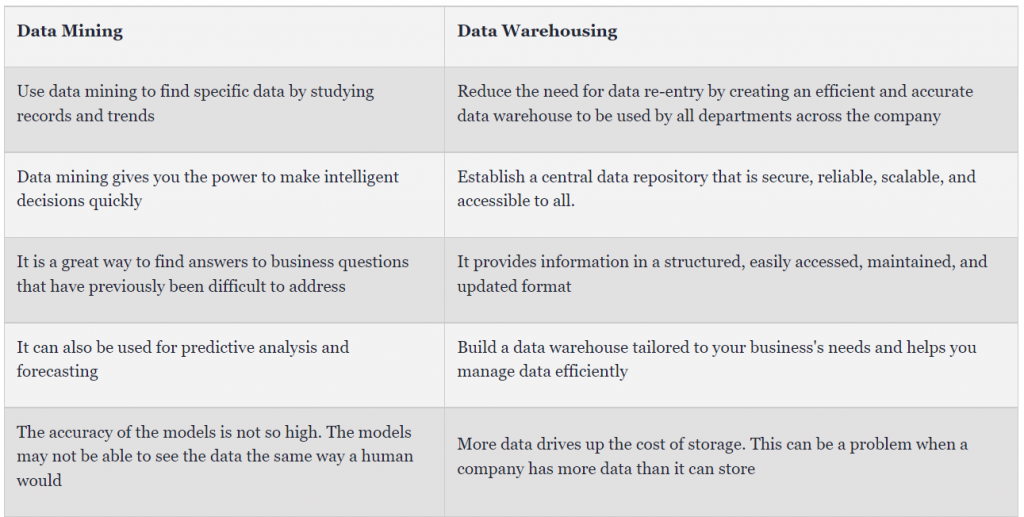
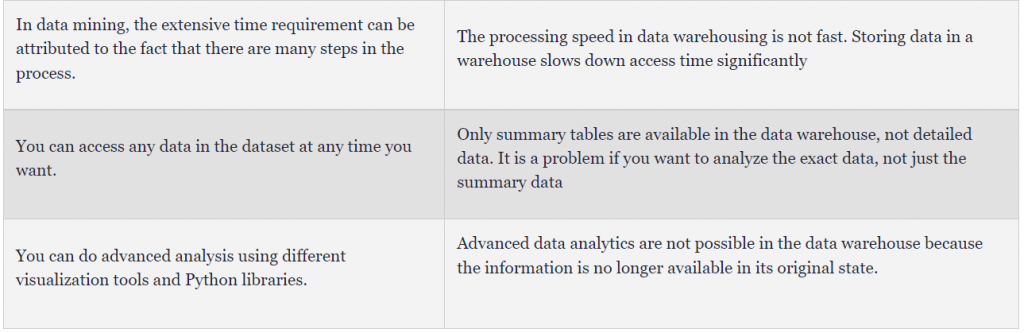
Abschluss
Vielen Dank für das Lesen unseres Artikels. Wir hoffen, er hilft Ihnen, den Unterschied zwischen Data Mining und Data Warehousing besser zu verstehen. Wenn Sie mehr über Data Mining und Data Warehousing erfahren möchten, besuchen Sie bitte: Gudu SQLFlow für weitere Informationen.
Als einer der die besten Datenherkunftstools Gudu SQLFlow ist ab 2022 auf dem Markt erhältlich und kann nicht nur SQL-Skriptdateien analysieren, sondern auch Datenherkunft, und führen Sie eine visuelle Anzeige durch, ermöglichen Sie Benutzern aber auch, die Datenherkunft im CSV-Format bereitzustellen und eine visuelle Anzeige durchzuführen. (Veröffentlicht von Ryan am 10. August 2022)
Testen Sie Gudu SQLFlow Live

Wenn Ihnen dies gefällt, sehen Sie sich bitte auch unsere anderen Artikel unten an:


