Entwicklung der Metadatenarchitektur
Metadatenverwaltung ist die Grundlage und Quelle der Datenverwaltung System. In verschiedenen Phasen der technologischen Entwicklung unterscheiden sich Status und Rolle in der Datenverwaltung von Unternehmen erheblich. Daten zeichnen sich heute durch Multi-Source-Charakter, Heterogenität und Wertunterschiede aus, die sich im rasanten Datenwachstum noch weiter beschleunigen und verstärken. Da die Rechenleistung von Unternehmen deutlich zugenommen hat, besteht zudem die Erwartung, Daten tiefer auszuwerten, um einen höheren Nutzen zu erzielen.
Als Support-Team für Unternehmensdaten hören wir täglich am häufigsten die Frage: „Wie erhalte ich den richtigen Datensatz?“ Wir haben festgestellt, dass unsere Teams trotz hochskalierbarer Datenspeicherung, Echtzeit-Computing und vielem mehr immer noch Zeit mit der Suche nach den richtigen Datensätzen für Entwicklung und Analyse verschwenden. Das heißt, es mangelt uns immer noch an der Verwaltung von Datenbeständen. Tatsächlich bieten viele Unternehmen Open-Source-Lösungen für die oben genannten Probleme an, insbesondere Tools zur Datenermittlung und Metadatenverwaltung.
Da die Geschäfts- und Technologieentwicklungsbedürfnisse verschiedener Unternehmen in verschiedenen Phasen jedoch begrenzt sind, variiert die Auswahl der Funktionen, Anwendungen und Schwerpunkte für den Aufbau relevanter Managementplattformen durch Unternehmen häufig stark. Dieser Artikel stellt die architektonische Entwicklung von Tools zur Metadatenverwaltung.
Vereinfacht ausgedrückt ist Metadatenmanagement die effiziente Organisation und Verwaltung von Datenbeständen mithilfe von Metadaten. Es unterstützt Datenexperten beim Sammeln, Organisieren, Zugreifen und Anreichern von Metadaten und unterstützt übergeordnete Anwendungen wie Datenzuordnungen, Datenspezifikation, Kostenkontrolle, Qualitätsprüfung und Sicherheitsaudits.
Vor dreißig Jahren war ein Datenbestand vielleicht nur eine Tabelle in einer Oracle-Datenbank. In modernen Unternehmen gibt es jedoch eine verwirrende Vielfalt unterschiedlicher Datenbestandstypen. Es kann sich um eine relationale Datenbanktabelle, ein Objekt in einer nicht-relationalen Datenbank, ein Echtzeit-Streaming-Datenelement, einen Indikator, ein Porträt oder ein Zifferblatt bzw. ein Panel in einem BI-Tool handeln.
Ein modernes Metadatenmanagementsystem sollte alle Arten von Datenbeständen abdecken und Datenarbeitern helfen, die zugehörigen Datenbestände besser zu nutzen. Daher sind die Kernfunktionen eines Metadatenmanagementsystems heute wie folgt:
- Suche und Entdeckung: Datentabellen, Felder, Tags, Nutzungsinformationen;
- Zugriffskontrolle: Zugriffskontrollgruppen, Benutzer, Richtlinien;
- Datenherkunft: Pipeline-Ausführung, Abfrage;
- Compliance: Klassifizierung von Datenschutz-/Compliance-Annotationstypen;
- Datenverwaltung: Datenquellenkonfiguration, Aufnahmekonfiguration, Aufbewahrungskonfiguration, Datenbereinigungsrichtlinie;
- Interpretierbarkeit und Reproduzierbarkeit von KI: Merkmalsdefinition, Modelldefinition, Ausführung von Trainingsläufen, Problemstellung;
- Datenmanipulation: Pipeline-Ausführung, verarbeitete Datenpartition, Datenstatistik;
- Datenqualität: Definition der Datenqualitätsregel, Ergebnis der Regelausführung, Datenstatistik.
Entwicklung der Metadatenarchitektur:
Der erste Generation Metadatenarchitektur basiert im Allgemeinen auf Extraktion. Metadaten werden durch Verbinden und Abfragen von Datenquellen (Hive, Kafka usw.) gewonnen, wobei lediglich externe Speicher- und Abfragedienste erforderlich sind. Es handelt sich in der Regel um ein klassisches monolithisches Frontend, das sich mit dem primären Speicher für Abfragen (meist MySQL/Postgres) verbindet. Ein Suchindex (meist Elasticsearch) bedient Suchanfragen, wenn die Abfrage die „rekursive Abfrage“-Grenze einer relationalen Datenbank erreicht. Er kann erweitert werden, um eine Graphdatenbank (meist Neo4j) als Abfrageindex zu verwenden.
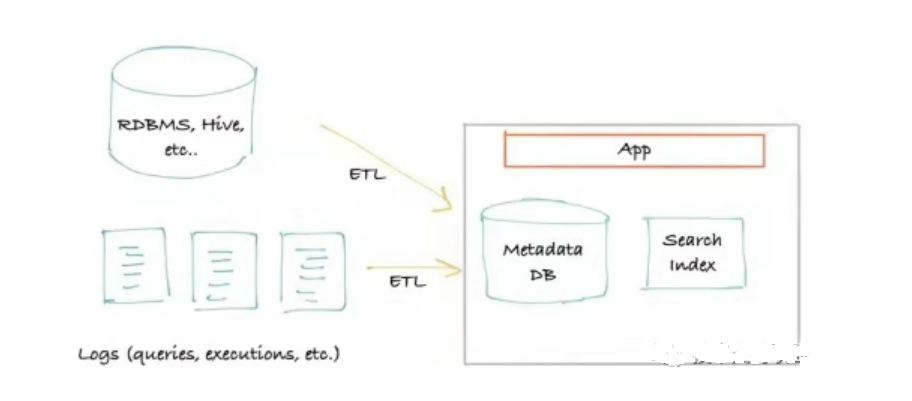
Die Vorteile dieser Metadatenarchitektur liegen auf der Hand: Sie ist einfach und kann schnell, effizient und kostengünstig mit nur Speicher und einer Suchmaschine erstellt werden. Die Nachteile liegen jedoch auf der Hand: Sie beeinträchtigt die Leistung der Datenquelle erheblich und stellt hohe Anforderungen an Extraktionszeit, -häufigkeit und -last. Da zudem die Echtzeitanforderungen immer höher werden, ist diese Metadatenarchitektur zunehmend ungeeignet.
Das Open-Source-Produkt Amundsen verfügt über eine Architektur der ersten Generation, konzentriert sich jedoch auf die Funktion der Erzielung eines Suchrankings, was sehr leistungsstark ist.
Der zweite Generation Metadatenarchitektur ist eine dreistufige Anwendungsarchitektur, die auf Service-Splitting basiert. Diese Architektur trennt die monolithische Anwendung von Metadatendiensten. Der Dienst bietet eine API, die das Schreiben von Metadaten in das System per Push-Mechanismus ermöglicht, sowie eine API zum Lesen von Metadaten für Programme, die Metadaten programmgesteuert lesen müssen.
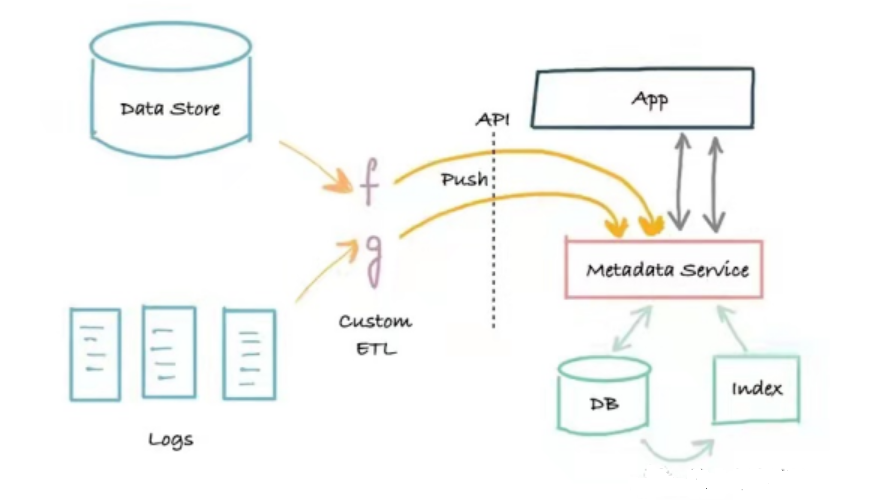
Der Vorteil dieser Architektur liegt in ihrer Push-basierten Implementierung, die eine Brücke zwischen Metadatenproduzent und Metadatendienst schlägt und das Echtzeitproblem löst. Der Nachteil ist, dass keine Protokolle vorhanden sind. Bei Problemen kann es schwierig sein, Such- und Graphenindizes zuverlässig zu booten (neu zu erstellen) oder zu reparieren. Metadatensysteme der zweiten Generation können oft ein zuverlässiges Such- und Discovery-Portal für die Datenbestände eines Unternehmens darstellen und die Kernbedürfnisse von Datenarbeitern erfüllen. Marquez verfügt über eine Metadatenarchitektur der zweiten Generation.
Der Metadatenarchitektur der dritten Generation ist eine ereignisbasierte Metadatenverwaltungsarchitektur, die auf Log-Push und Modellentkopplung basiert. Benutzer können je nach Bedarf auf unterschiedliche Weise mit der Metadatendatenbank interagieren und erweiterte Metadatenmodelle definieren.
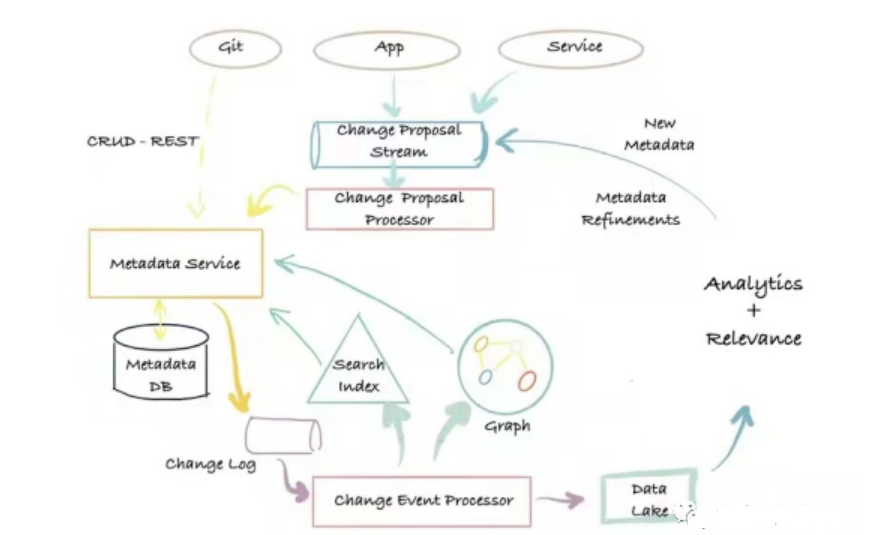
Die Hauptvorteile sind: Flexibilität, hohe Skalierbarkeit, Suche mit geringer Latenz, die Möglichkeit zur Volltext- und Rankingsuche nach Metadatenattributen, Graphabfragen mit Unterstützung von Metadatenbeziehungen sowie umfassende Scan- und Analysefunktionen. Der Nachteil: Es gibt viele abhängige Komponenten und hohe Betriebs- und Wartungskosten. Repräsentative Systeme der Metadatenarchitektur der dritten Generation sind Altas und DataHub.
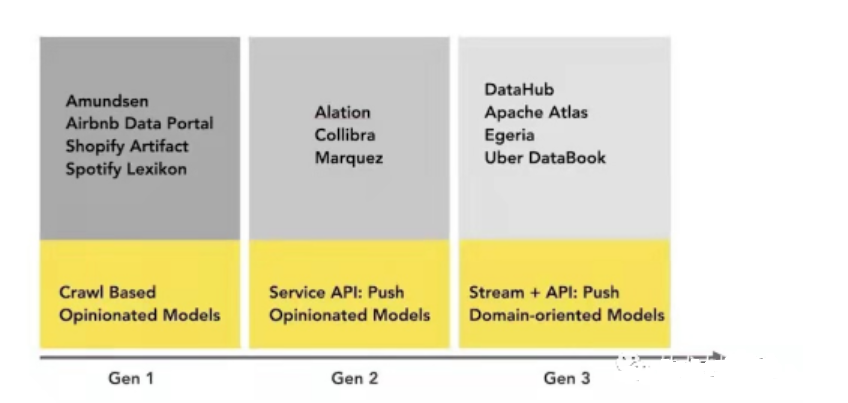
Eine einfache visuelle Darstellung der heutigen Landschaft der Metadatenverwaltungsplattformen (einschließlich nicht Open Source):
Abschluss
Vielen Dank für das Lesen unseres Artikels. Wir hoffen, er hilft Ihnen, die Entwicklung der Metadatenarchitektur besser zu verstehen. Wenn Sie mehr über Metadaten erfahren möchten, besuchen Sie bitte Gudu SQLFlow für weitere Informationen.
Als einer der die besten Datenherkunftstools Gudu SQLFlow ist heute auf dem Markt erhältlich und kann nicht nur SQL-Skriptdateien analysieren, die Datenherkunft ermitteln und eine visuelle Anzeige durchführen, sondern ermöglicht Benutzern auch, die Datenherkunft im CSV-Format bereitzustellen und eine visuelle Anzeige durchzuführen. (Veröffentlicht von Ryan am 29. Juni 2022)