メタデータ アーキテクチャの進化
メタデータ管理 の基礎であり、源である データガバナンス システム。技術開発のさまざまな段階で、エンタープライズ データ ガバナンスにおけるそのステータスと役割は大きく異なります。今日、データにはマルチソース、異質性、価値の相違という特徴があり、これらの特徴はデータの狂った成長の過程で加速され、増幅されます。さらに、企業のコンピューティング能力が一般的に大幅に向上した後、より大きな価値を発揮するために、より深い方法でデータをマイニングすることが強く期待されています。
エンタープライズ データのサポート チームとして、日常生活で最も多く耳にする質問は、「正しいデータ セットを取得する方法」です。高度にスケーラブルなデータ ストレージやリアルタイム コンピューティングなどを構築してきましたが、開発と分析に適したデータセットを見つけるのにチームがまだ時間を浪費していることに気付きました。つまり、データ資産の管理がまだ不足しています。実際、上記の問題に対するオープンソース ソリューション、つまりデータ検出ツールとメタデータ管理ツールを提供している企業は数多くあります。
ただし、さまざまな段階のさまざまな企業のビジネスおよび技術開発のニーズによって制限されるため、企業が関連する管理プラットフォームを構築するための機能、アプリケーション、および焦点の方向性の選択は、しばしば大きく異なります。この記事は、アーキテクチャの進化を紹介することを目的としています メタデータ管理ツール.
簡単に言うと、メタデータ管理とは、メタデータを使用してデータ資産を効率的に編成および管理することです。また、データ プロフェッショナルがメタデータを収集、整理、アクセス、強化し、データ マップ、データ仕様、コスト管理、品質検査、セキュリティ監査などの上位層アプリケーションをサポートするのにも役立ちます。
30 年前、データ資産は Oracle データベース内の単なるテーブルであった可能性があります。しかし、現代の企業では、当惑するほどさまざまな種類のデータ資産があります。これは、リレーショナル データベース テーブル、非リレーショナル データベース内のオブジェクト、リアルタイム ストリーミング データの一部、インジケータ、ポートレート、または BI ツールのダイヤルまたはパネルである場合があります。
最新のメタデータ管理システムは、すべてのタイプのデータ資産をカバーし、データ ワーカーが関連するデータ資産をより有効に活用できるようにする必要があります。したがって、今日適用可能なメタデータ管理システムのコア機能は次のとおりです。
- 検索と発見: データテーブル、フィールド、タグ、使用情報;
- アクセス制御: アクセス制御グループ、ユーザー、ポリシー。
- データ系統: パイプラインの実行、クエリ;
- コンプライアンス: データのプライバシー/コンプライアンスの注釈タイプの分類。
- データ管理: データ ソース構成、取り込み構成、保持構成、データ パージ ポリシー。
- AI の解釈可能性、再現性: 機能の定義、モデルの定義、トレーニングの実行、問題の記述。
- データ操作: パイプラインの実行、処理されたデータ パーティション、データ統計。
- データ品質: データ品質ルール定義、ルール実行結果、データ統計。
メタデータ アーキテクチャの進化:
の 初代 メタデータ アーキテクチャ 一般的に抽出に基づいています。メタデータは、データ ソース (Hive、Kafka など) に接続してクエリを実行することによって取得され、外部ストレージとクエリ サービスのみが必要です。これは通常、クエリ用のプライマリ ストレージ (通常は MySQL/Postgres)、クエリがリレーショナル データベースの「再帰クエリ」制限に達したときに検索クエリを提供する検索インデックス (通常は Elasticsearch) に接続する従来のモノリシック フロント エンドです。クエリ インデックスとしてグラフ データベース (通常は Neo4j) を使用するようにアップグレードする必要があります。
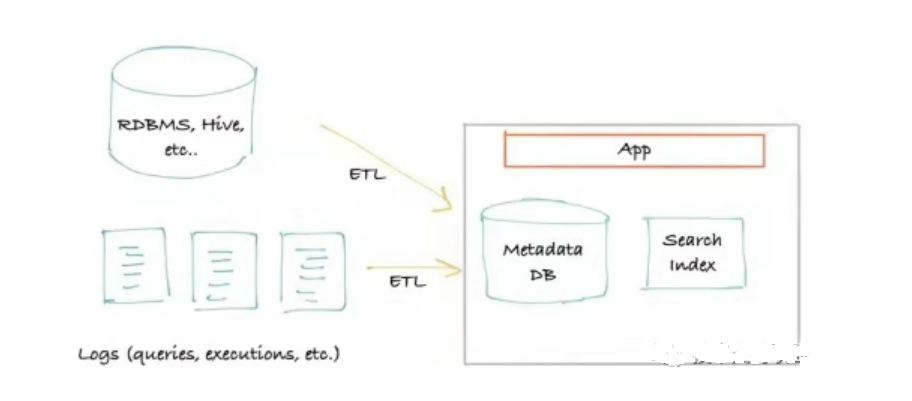
メタデータ アーキテクチャ
このメタデータ アーキテクチャの利点は明らかです。アーキテクチャがシンプルで、ストレージと検索エンジンだけですばやく構築でき、高効率で低コストです。しかし、欠点も明らかです。データ ソースのパフォーマンスにかなりの影響を与え、抽出時間、頻度、および負荷に関する多くの要件があります。さらに、リアルタイム要件がますます高くなるにつれて、このメタデータ アーキテクチャはますます適用できなくなりつつあります。
オープンソース製品の Amundsen は第一世代のアーキテクチャを持っていますが、非常に強力な検索ランキングを達成する機能に焦点を当てています。
の 第2世代 メタデータ アーキテクチャ サービス分割に基づく 3 層アプリケーション アーキテクチャです。このアーキテクチャは、モノリシック アプリケーションをメタデータ サービスから分離します。このサービスは、プッシュ メカニズムを使用してメタデータをシステムに書き込むことができる API と、メタデータをプログラムで読み取る必要があるプログラム用のメタデータ読み取り API を提供します。
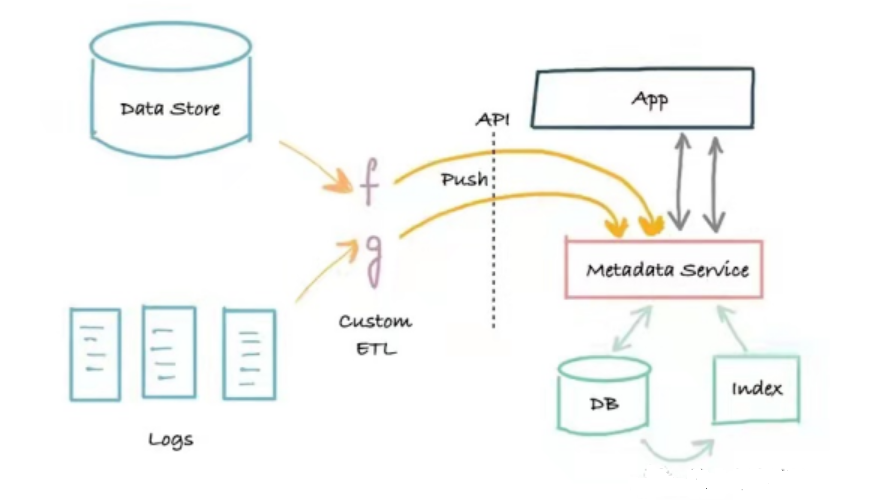
メタデータ アーキテクチャ
このアーキテクチャの利点は、メタデータ プロデューサーとメタデータ サービスの間にブリッジを構築し、リアルタイムの問題を解決するプッシュ メソッドに基づいて実装されることです。欠点は、ログがないことです。何か問題が発生した場合、確実にブートストラップ (再作成) したり、検索およびグラフのインデックスを修正したりすることが困難になる場合があります。第 2 世代のメタデータ システムは、多くの場合、企業のデータ資産の信頼できる検索および発見ポータルとなり、データ ワーカーの主要なニーズに対応します。Marquez は第 2 世代のメタデータ アーキテクチャを採用しています。
の 第 3 世代のメタデータ アーキテクチャ は、ログ プッシュ + モデル分離に基づく、イベント ベースのメタデータ管理アーキテクチャです。ユーザーは、ニーズに応じてさまざまな方法でメタデータ データベースを操作し、拡張メタデータ モデルを定義できます。
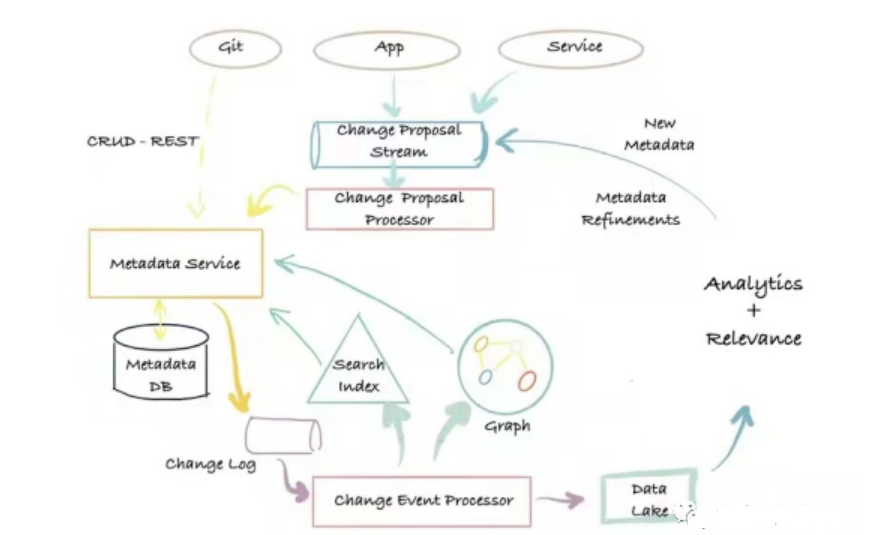
メタデータ アーキテクチャ
その主な利点は次のとおりです。柔軟性、高いスケーラビリティ、低待機時間の検索、メタデータ属性でフルテキストおよびランキング検索を実行する機能、メタデータの関係をサポートするグラフ クエリ、およびフル スキャンと分析機能。欠点は、従属コンポーネントが多く、運用と保守のコストが高いことです。第 3 世代のメタデータ アーキテクチャの代表的なシステムは、Altas と DataHub です。
今日のメタデータ管理プラットフォームの状況 (非オープン ソースを含む) の単純な視覚的表現:
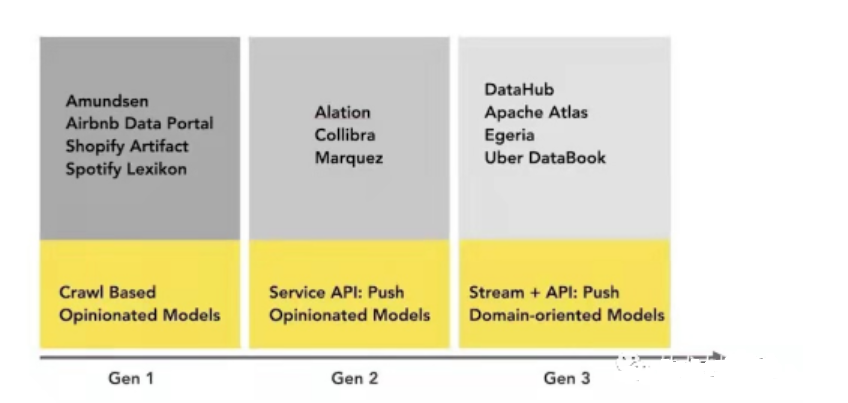
結論
この記事をお読みいただきありがとうございます。この記事が、メタデータ アーキテクチャの進化をよりよく理解するのに役立つことを願っています。メタデータについて詳しく知りたい場合は、こちらをご覧になることをお勧めします。 Gudu SQLFlow 詳細については。
その一つとして 最高のデータ系統ツール 現在市場に出回っている Gudu SQLFlow は、SQL スクリプト ファイルを分析し、データ系統を取得して視覚的に表示できるだけでなく、ユーザーがデータ系統を CSV 形式で提供し、視覚的に表示することもできます。 (2022 年 6 月 29 日に Ryan により公開)

これを読んで楽しんでいる場合は、以下の他の記事をご覧ください。


