Évolution de l'architecture des métadonnées
Gestion des métadonnées est le fondement et la source de la gouvernance des données Système. À différents stades de développement technologique, son statut et son rôle dans la gouvernance des données d'entreprise varient considérablement. Aujourd'hui, les données se caractérisent par leur multi-source, leur hétérogénéité et leurs différences de valeur, des caractéristiques qui s'amplifient et s'amplifient avec la croissance fulgurante des données. De plus, la puissance de calcul des entreprises ayant globalement augmenté de manière significative, il existe une forte attente quant à une exploitation plus approfondie des données pour en tirer une plus grande valeur.
En tant qu'équipe de support des données d'entreprise, la question que nous entendons le plus souvent au quotidien est « comment obtenir le bon ensemble de données ». Nous avons constaté que, malgré la mise en place de solutions de stockage de données hautement évolutives, de calcul en temps réel et bien plus encore, nos équipes perdent encore du temps à trouver les bons ensembles de données à développer et à analyser. Autrement dit, nous manquons encore de gestion des données. De nombreuses entreprises proposent d'ailleurs des solutions open source à ces problèmes, notamment des outils de découverte de données et de gestion des métadonnées.
Cependant, étant donné les contraintes liées aux besoins de développement commercial et technologique des entreprises à différents stades de développement, le choix des fonctions, des applications et des axes prioritaires pour la construction de plateformes de gestion pertinentes varie souvent considérablement. Cet article présente l'évolution architecturale de outils de gestion des métadonnées.
En termes simples, la gestion des métadonnées consiste à organiser et à gérer efficacement les données à l'aide de métadonnées. Elle peut également aider les professionnels des données à collecter, organiser, consulter et enrichir les métadonnées, et à prendre en charge des applications de couche supérieure telles que la cartographie des données, la spécification des données, le contrôle des coûts, le contrôle qualité et l'audit de sécurité.
Il y a trente ans, une ressource de données pouvait se résumer à une simple table dans une base de données Oracle. Aujourd'hui, l'entreprise dispose d'une multitude de types de ressources de données. Il peut s'agir d'une table de base de données relationnelle, d'un objet dans une base de données non relationnelle, d'un flux de données en temps réel, d'un indicateur, d'un portrait, d'un cadran ou d'un panneau dans un outil de BI.
Un système moderne de gestion des métadonnées doit couvrir tous les types de données et permettre aux professionnels de la donnée d'optimiser leur exploitation. Par conséquent, les principales fonctions d'un système de gestion des métadonnées aujourd'hui applicables sont les suivantes :
- Recherche et découverte : tables de données, champs, balises, informations d'utilisation ;
- Contrôle d'accès : groupes de contrôle d'accès, utilisateurs, politiques ;
- Lignée de données: exécution du pipeline, requête ;
- Conformité : classification des types d’annotations relatives à la confidentialité/conformité des données ;
- Gestion des données : configuration de la source de données, configuration de l'ingestion, configuration de la rétention, politique de purge des données ;
- Interprétabilité et reproductibilité de l'IA : définition des fonctionnalités, définition du modèle, exécution de l'entraînement, énoncé du problème ;
- Manipulation des données : exécution du pipeline, partition des données traitées, statistiques des données ;
- Qualité des données: définition de règle de qualité des données, résultat d'exécution de règle, statistiques de données.
Évolution de l'architecture des métadonnées :
Le première génération architecture des métadonnées Il est généralement basé sur l'extraction. Les métadonnées sont obtenues en connectant et en interrogeant des sources de données (Hive, Kafka, etc.), et seuls un stockage externe et des services de requêtes sont requis. Il s'agit généralement d'une interface monolithique classique qui se connecte au stockage principal pour les requêtes (généralement MySQL/Postgres), d'un index de recherche (généralement Elasticsearch) qui traite les requêtes lorsque celles-ci atteignent la limite de « requête récursive » d'une base de données relationnelle, et peut être mis à niveau pour utiliser une base de données graphique (généralement Neo4j) comme index de requête.
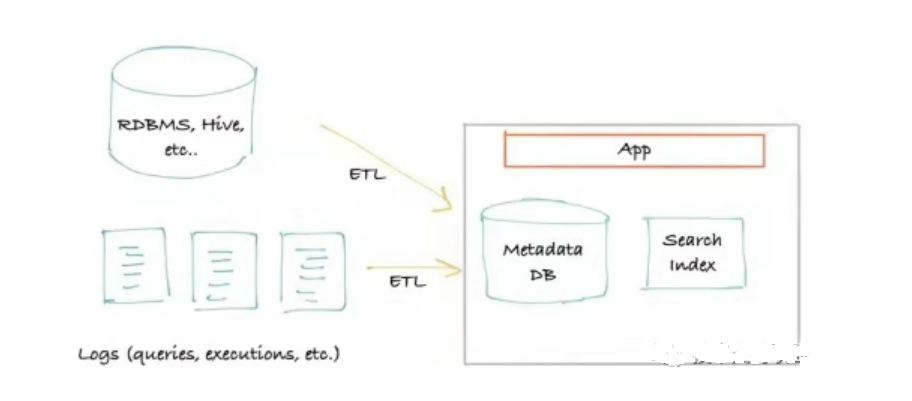
Architecture des métadonnées
Les avantages de cette architecture de métadonnées sont évidents : elle est simple et peut être construite rapidement, avec seulement du stockage et un moteur de recherche, avec une grande efficacité et un faible coût. Cependant, ses inconvénients sont également évidents : elle a un impact considérable sur les performances de la source de données, et les exigences en matière de temps, de fréquence et de charge d'extraction sont nombreuses. De plus, face à des exigences de plus en plus élevées en temps réel, cette architecture de métadonnées devient de plus en plus inapplicable.
Le produit open source Amundsen possède une architecture de première génération, mais il se concentre sur la fonction d'obtention d'un classement de recherche, ce qui est très puissant.
Le deuxième génération architecture des métadonnées Il s'agit d'une architecture applicative à trois niveaux basée sur la séparation des services. Cette architecture sépare l'application monolithique des services de métadonnées. Le service fournit une API permettant l'écriture de métadonnées dans le système via un mécanisme de push, ainsi qu'une API de lecture de métadonnées pour les programmes nécessitant une lecture programmatique des métadonnées.
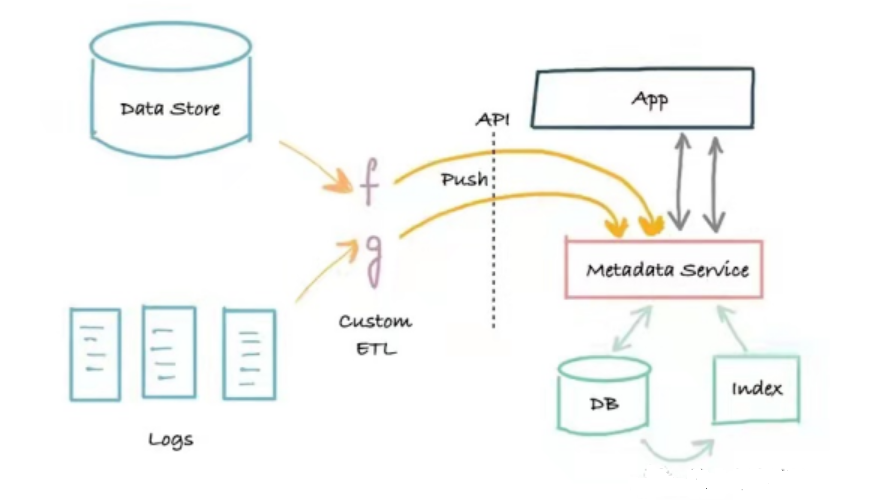
Architecture des métadonnées
L'avantage de cette architecture réside dans sa mise en œuvre basée sur la méthode push, qui établit un pont entre le producteur de métadonnées et le service de métadonnées, et résout le problème du temps réel. L'inconvénient est l'absence de journaux. En cas de problème, il peut être difficile d'amorcer (recréer) ou de corriger de manière fiable les index de recherche et de graphes. Les systèmes de métadonnées de deuxième génération constituent souvent un portail de recherche et de découverte fiable pour les données d'une entreprise, répondant aux besoins essentiels des professionnels de la donnée. Marquez dispose d'une architecture de métadonnées de deuxième génération.
Le architecture de métadonnées de troisième génération Il s'agit d'une architecture de gestion de métadonnées basée sur les événements, basée sur le découplage des modèles et la transmission des journaux. Les utilisateurs peuvent interagir avec la base de métadonnées de différentes manières selon leurs besoins et définir des modèles de métadonnées étendus.
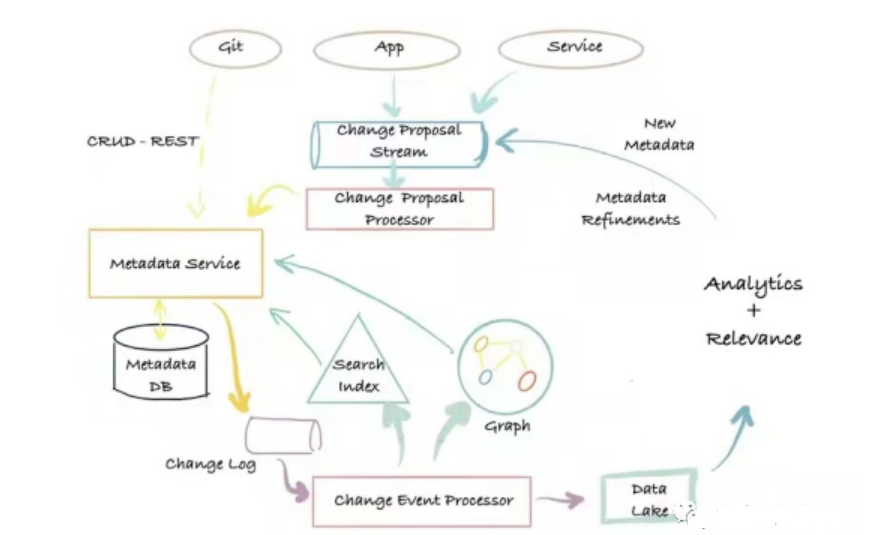
Architecture des métadonnées
Ses principaux avantages sont : flexibilité, grande évolutivité, recherche à faible latence, possibilité d'effectuer des recherches en texte intégral et par classement sur les attributs de métadonnées, requêtes graphiques prenant en charge les relations entre métadonnées, et capacités complètes d'analyse. L'inconvénient réside dans la multitude de composants dépendants et les coûts d'exploitation et de maintenance élevés. Les systèmes représentatifs de l'architecture de métadonnées de troisième génération sont Altas et DataHub.
Une représentation visuelle simple du paysage actuel des plateformes de gestion des métadonnées (y compris les sources non open source) :
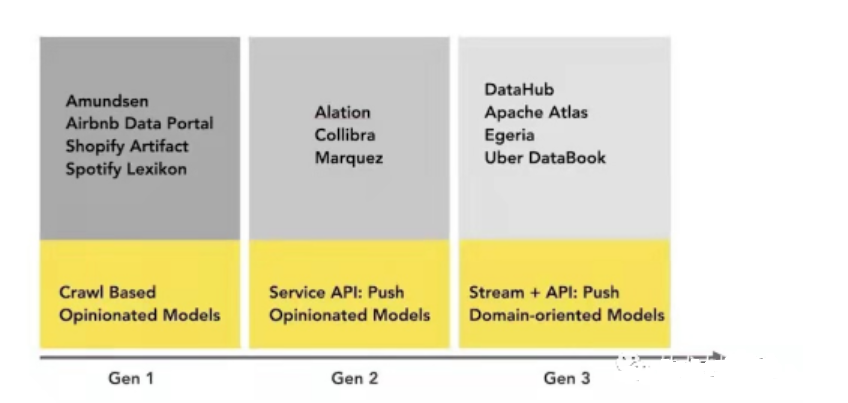
Conclusion
Merci d'avoir lu notre article et nous espérons qu'il vous aidera à mieux comprendre l'évolution de l'architecture des métadonnées. Pour en savoir plus sur les métadonnées, nous vous conseillons de consulter notre site. Gudu SQLFlow pour plus d'informations.
En tant que l'un des meilleurs outils de lignage de données Disponible sur le marché aujourd'hui, Gudu SQLFlow peut non seulement analyser les fichiers de script SQL, obtenir la lignée des données et effectuer un affichage visuel, mais également permettre aux utilisateurs de fournir la lignée des données au format CSV et d'effectuer un affichage visuel. (Publié par Ryan le 29 juin 2022)
Essayez Gudu SQLFlow Live

Si vous aimez lire ceci, alors n'hésitez pas à explorer nos autres articles ci-dessous :


