Evolución de la arquitectura de metadatos
Gestión de metadatos es el fundamento y la fuente de la gobernanza de datos Sistema. En las diferentes etapas del desarrollo tecnológico, su estatus y rol en la gobernanza de datos empresariales varían considerablemente. Hoy en día, los datos se caracterizan por su multiorigen, heterogeneidad y diferencia de valor, características que se aceleran y amplifican en el proceso de crecimiento exponencial de los datos. Además, tras el significativo aumento generalizado de la capacidad de procesamiento de las empresas, existe una fuerte expectativa de que los datos se exploten a mayor profundidad para obtener mayor valor.
Como equipo de soporte de datos empresariales, la pregunta más frecuente a diario es "¿cómo obtener el conjunto de datos correcto?". Nos hemos dado cuenta de que, si bien hemos desarrollado almacenamiento de datos altamente escalable, computación en tiempo real y más, nuestros equipos siguen perdiendo tiempo buscando los conjuntos de datos adecuados para desarrollar y analizar. Es decir, aún carecemos de la gestión de activos de datos. De hecho, muchas empresas ofrecen soluciones de código abierto para estos problemas, como herramientas de descubrimiento de datos y gestión de metadatos.
Sin embargo, debido a las limitaciones de las necesidades de desarrollo empresarial y tecnológico de las distintas empresas en sus distintas etapas, la selección de funciones, aplicaciones y enfoques para la construcción de plataformas de gestión relevantes por parte de las empresas suele variar considerablemente. Este artículo pretende presentar la evolución arquitectónica de... herramientas de gestión de metadatos.
En pocas palabras, la gestión de metadatos consiste en la organización y gestión eficiente de activos de datos mediante metadatos. También ayuda a los profesionales de datos a recopilar, organizar, acceder y enriquecer metadatos, y a respaldar aplicaciones de nivel superior como mapas de datos, especificación de datos, control de costes, inspección de calidad y auditoría de seguridad.
Hace treinta años, un activo de datos podía ser simplemente una tabla en una base de datos Oracle. Sin embargo, en la empresa moderna, disponemos de una asombrosa variedad de tipos de activos de datos. Puede ser una tabla de una base de datos relacional, un objeto en una base de datos no relacional, un fragmento de datos en tiempo real, un indicador, un retrato, un dial o un panel en una herramienta de inteligencia empresarial.
Un sistema moderno de gestión de metadatos debe abarcar todo tipo de activos de datos y ayudar a los profesionales de datos a optimizar su uso. Por lo tanto, las funciones principales del sistema de gestión de metadatos aplicable hoy en día son las siguientes:
- Búsqueda y descubrimiento: tablas de datos, campos, etiquetas, información de uso;
- Control de acceso: grupos de control de acceso, usuarios, políticas;
- Linaje de datos: ejecución de canalización, consulta;
- Cumplimiento: clasificación de tipos de anotaciones de privacidad/cumplimiento de datos;
- Gestión de datos: configuración de la fuente de datos, configuración de ingesta, configuración de retención, política de purga de datos;
- Interpretabilidad y reproducibilidad de la IA: definición de características, definición del modelo, ejecución de entrenamiento, planteamiento del problema;
- Manipulación de datos: ejecución de canalización, partición de datos procesados, estadísticas de datos;
- Calidad de los datos: definición de regla de calidad de datos, resultado de ejecución de regla, estadísticas de datos.
Evolución de la arquitectura de metadatos:
El primera generación arquitectura de metadatos Generalmente se basa en la extracción. Los metadatos se obtienen conectando y consultando fuentes de datos (Hive, Kafka, etc.), y solo se requieren servicios de almacenamiento y consulta externos. Suele ser un front-end monolítico clásico que se conecta al almacenamiento principal para las consultas (normalmente MySQL/Postgres), un índice de búsqueda (normalmente Elasticsearch) que procesa las consultas cuando esta alcanza el límite de consultas recursivas de una base de datos relacional. Puede actualizarse para usar una base de datos gráfica (normalmente Neo4j) como índice de consulta.
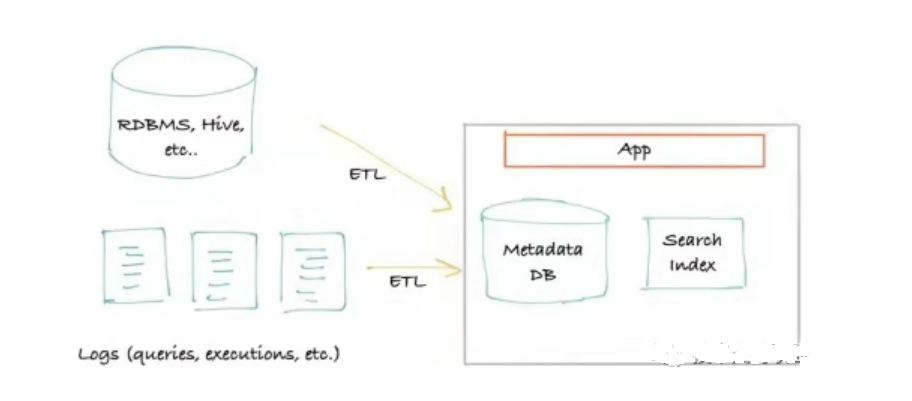
Las ventajas de esta arquitectura de metadatos son evidentes: es simple y se puede construir rápidamente con solo almacenamiento y un motor de búsqueda, con alta eficiencia y bajo costo. Sin embargo, las desventajas también son evidentes: tiene un impacto considerable en el rendimiento de la fuente de datos y existen muchos requisitos en cuanto al tiempo de extracción, la frecuencia y la carga. Además, a medida que los requisitos de tiempo real aumentan, esta arquitectura de metadatos se vuelve cada vez más inaplicable.
El producto de código abierto Amundsen tiene una arquitectura de primera generación, pero se centra en la función de lograr ranking de búsqueda, que es muy potente.
El segunda generación arquitectura de metadatos Es una arquitectura de aplicación de tres niveles basada en la división de servicios. Esta arquitectura separa la aplicación monolítica de los servicios de metadatos. El servicio proporciona una API que permite escribir metadatos en el sistema mediante un mecanismo de inserción y una API de lectura de metadatos para programas que necesitan leerlos programáticamente.
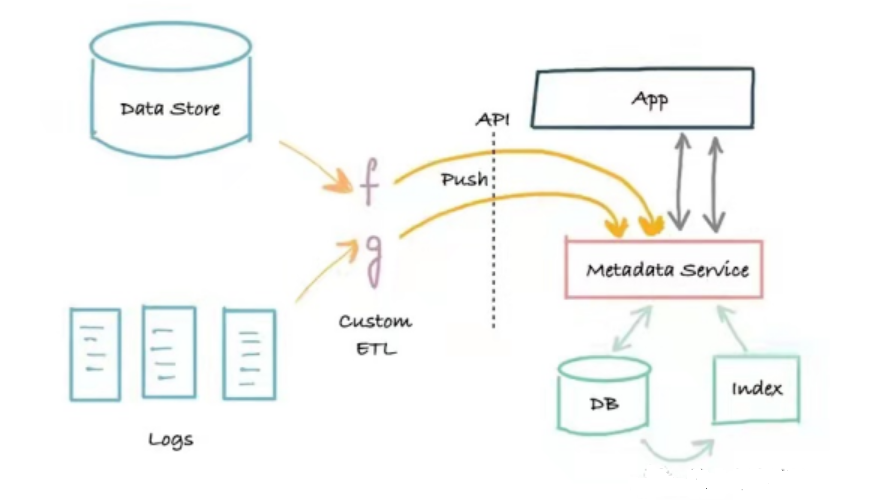
La ventaja de esta arquitectura es que se implementa con el método push, que conecta al productor de metadatos con el servicio de metadatos y resuelve el problema del tiempo real. La desventaja es que no se generan registros. Si algo falla, puede resultar difícil reiniciar (recrear) o corregir de forma fiable los índices de búsqueda y gráficos. Los sistemas de metadatos de segunda generación suelen ser un portal fiable de búsqueda y descubrimiento para los activos de datos de una empresa, satisfaciendo las necesidades básicas de los trabajadores de datos. Marquez cuenta con una arquitectura de metadatos de segunda generación.
El arquitectura de metadatos de tercera generación Es una arquitectura de gestión de metadatos basada en eventos, basada en la inserción de registros y la disociación de modelos. Los usuarios pueden interactuar con la base de datos de metadatos de diferentes maneras según sus necesidades y definir modelos de metadatos extendidos.
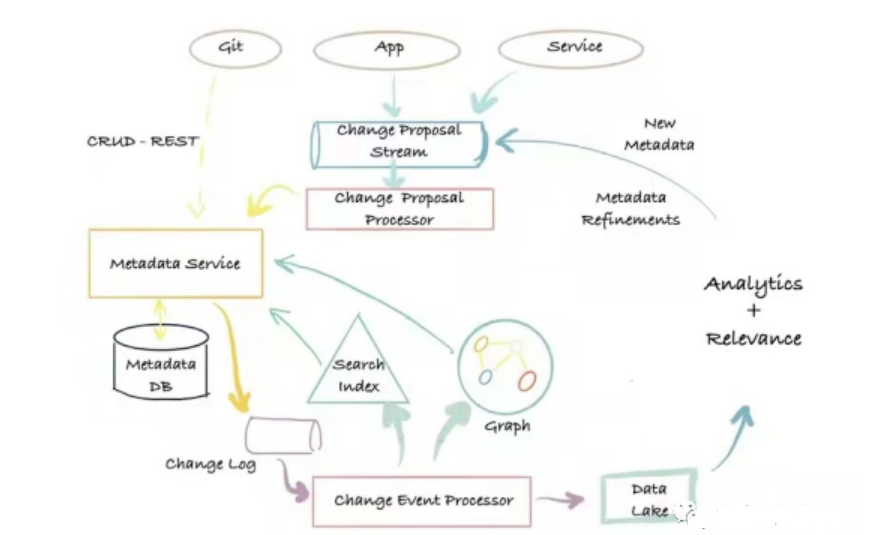
Sus principales ventajas son: flexibilidad, alta escalabilidad, búsqueda de baja latencia, capacidad para realizar búsquedas de texto completo y de clasificación de atributos de metadatos, consultas gráficas que admiten relaciones entre metadatos y capacidades completas de escaneo y análisis. La desventaja es la gran cantidad de componentes dependientes y el alto costo de operación y mantenimiento. Los sistemas representativos de la arquitectura de metadatos de tercera generación son Altas y DataHub.
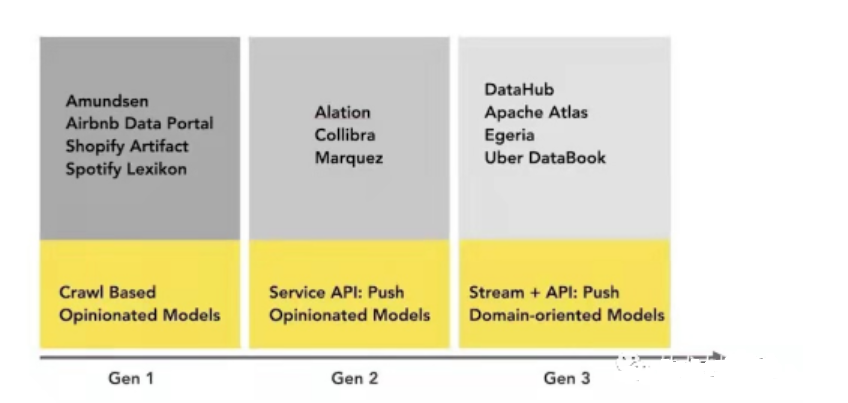
Una representación visual simple del panorama actual de las plataformas de gestión de metadatos (incluso las que no son de código abierto):
Conclusión
Gracias por leer nuestro artículo. Esperamos que le ayude a comprender mejor la evolución de la arquitectura de metadatos. Si desea obtener más información sobre metadatos, le recomendamos visitar Flujo de SQL de Gudu Para más información.
Como uno de los Las mejores herramientas de linaje de datos Disponible actualmente en el mercado, Gudu SQLFlow no solo puede analizar archivos de script SQL, obtener linaje de datos y realizar una visualización, sino que también permite a los usuarios proporcionar linaje de datos en formato CSV y realizar una visualización. (Publicado por Ryan el 29 de junio de 2022)