Wie Sie vielleicht wissen, ist die Datenherkunft im Unternehmensumfeld sehr wichtig.
Es erkennt den Datenfluss/die Datenbewegung von der Quelle zum Ziel über verschiedene Änderungen und Sprünge auf seinem Weg.
In diesem Artikel zeige ich Ihnen drei Möglichkeiten, die Datenherkunft in SQL zu erfassen und die Änderungen und Sprünge in nur 1 Minute in einer CSV-Datei zu speichern.
Wenn Sie diese CSV-Datei zur Hand haben, können Sie sie mit Microsoft Excel öffnen, um die Datenbewegung zu analysieren oder die Metadaten in der CSV-Datei zur weiteren Untersuchung in Ihren Datenkatalog zu importieren.
1. Verwenden Sie das SQLFlow Cloud-Web
Nach dem Öffnen der Site: https://sqlflow.gudusoft.com, fügen Sie einfach das zu analysierende SQL-Skript ein oder laden Sie eine ZIP-Datei mit mehreren SQL-Dateien hoch.
Nachdem Sie auf die Schaltfläche „Visualisieren“ geklickt haben, wird die Datenherkunft wie folgt visualisiert. Sie können das Ergebnis in einer CSV-Datei herunterladen.

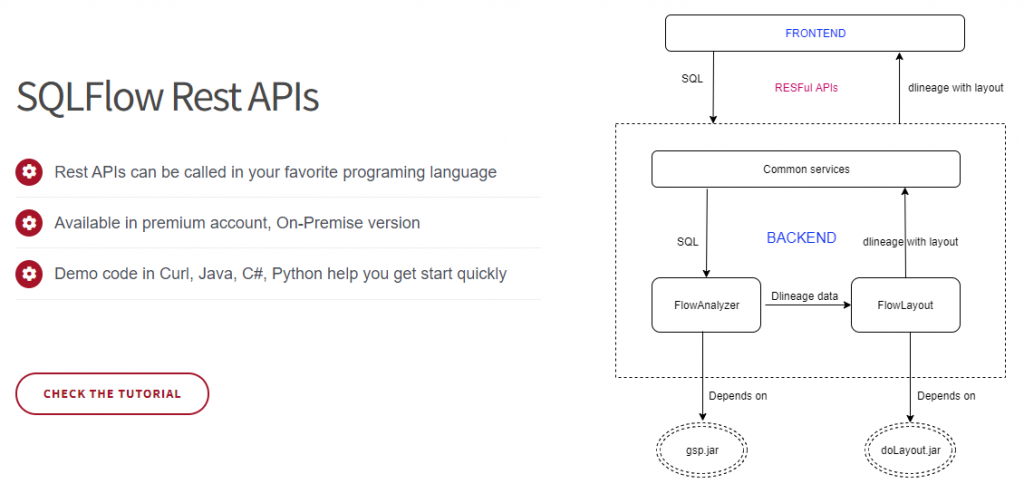
2. Verwenden Sie die SQLFlow Rest API
Sie können eine einzelne SQL-Datei oder eine ZIP-Datei mit mehreren SQL-Dateien in Ihrer bevorzugten Programmiersprache wie Java, Python, C# usw. an den SQLFlow-Server senden.
und geben Sie die gewünschte Datenherkunft im CSV-, JSON- und Graphml-Format zurück.
Klicken Sie auf das Bild unten, um die ausführlichen Anweisungen anzuzeigen.
3. Verwenden Sie das Grabit-Tool
Sie können auch ein eigenständiges Tool verwenden: Grabit die SQL-Skripte aus dem Dateisystem, Github/Bitbucket und Datenbanken sammeln
und senden Sie es zur Analyse an SQLFlow, um die Datenherkunft im CSV-, JSON- und Graphml-Format zu erhalten.
Dieses Tool ist jetzt in der Beta-Phase, wenn Sie es ausprobieren möchten, einfach Melden Sie sich an und wir senden Ihnen die genaueren Informationen zu.
Testen Sie Gudu SQLFlow Live

Wenn Ihnen dies gefällt, sehen Sie sich bitte auch unsere anderen Artikel unten an: